Are LLMs All You Need for Task-Oriented Dialogue?
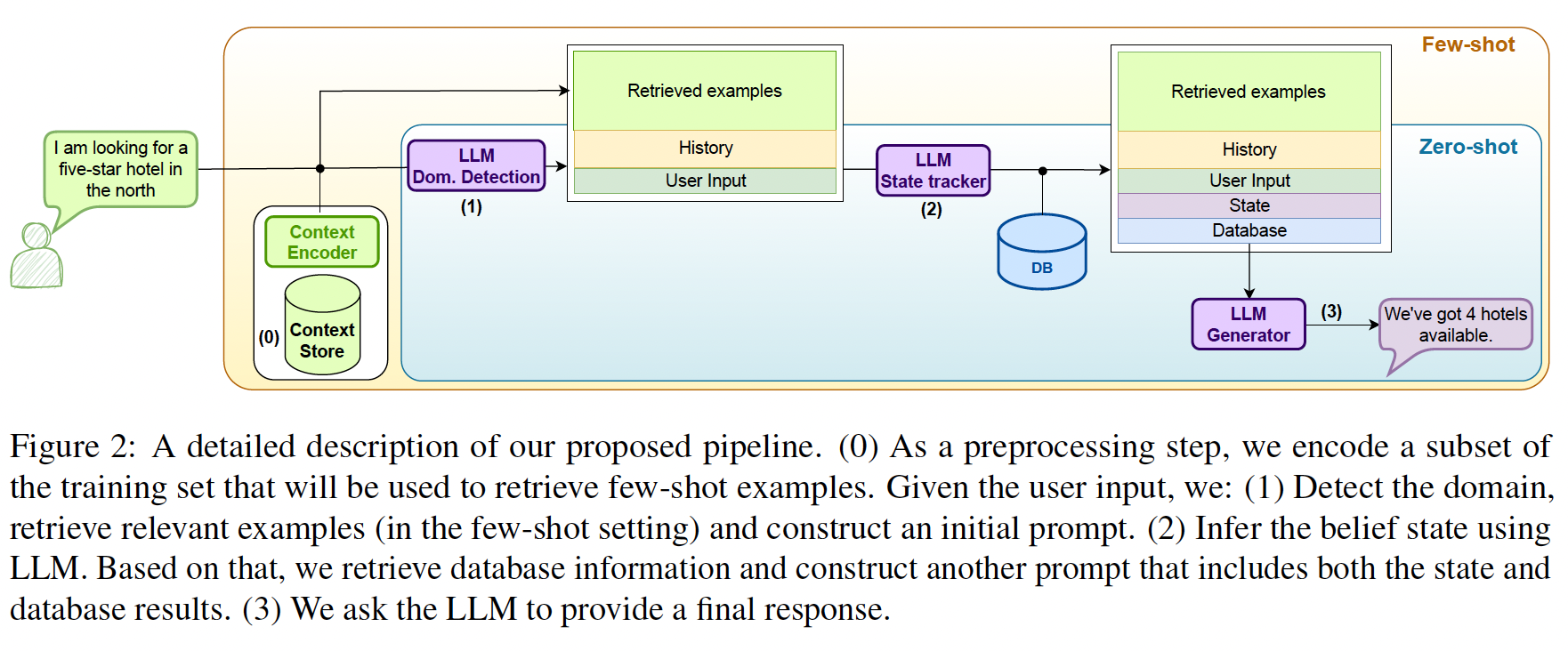
Instruction-finetuned large language models (LLMs) gained a huge popularity recently, thanks to their ability to interact with users through conversation. In this work, we aim to evaluate their ability to complete multi-turn tasks and interact with external databases in the context of established task-oriented dialogue benchmarks. We show that in explicit belief state tracking, LLMs underperform compared to specialized task-specific models. Nevertheless, they show some ability to guide the dialogue to a successful ending through their generated responses if they are provided with correct slot values. Furthermore, this ability improves with few-shot in-domain examples.
Introduction. Large Language Models (LLMs) have transformed the NLP field, showing outstanding performance across many NLP benchmarks such as Winograd Challenge (Levesque et al., 2012) or GLUE (Wang et al., 2018). Recently, instruction finetuning of LLMs proved to be able to align the model outputs with human preferences (Ouyang et al., 2022; Wang et al., 2022) and improved the LLMs’ communication capabilities substantially. State-of-theart LLMs are not only good at understanding user needs but also capable of providing relevant answers. Consequently, we see many chatbot applications both inside and outside academia (Chat- GPT1, Claude2, Sparrow3) which build upon the raw power of instruction-finetuned LLMs. Given the millions of daily interactions with these chatbots, it appears that the models are able to handle users’ needs to their satisfaction, at least to some extent. However, these chatbots are tuned using unstructured open-domain conversations.
Discussion / Conclusion. We present an experimental evaluation of instruction-tuned LLMs applied to the established task of task-oriented dialogue modeling, with five LLMs evaluated on two datasets. We find that LLMs are not performing well in terms of belief state tracking, even when provided with in-context fewshot examples. However, there is some potential to improve through prompt tuning and output parsing robust to irregularities. If provided with a correct belief state, the models can interact with the user successfully, provide useful information and fulfill the user’s needs. While the performance does not match the supervised state of the art, it is important to note that these models were not finetuned on in-domain data and work with just a domain description or a few examples (which again improve performance). Therefore, carefully picking representative ex- amples and combining the LLM with an in-domain belief tracker can be a viable choice for a taskoriented dialogue pipeline. Interestingly, in the human interactive evaluation, both ChatGPT and Tk-Instruct outperformed the expectations set by automatic metrics.