TREC iKAT 2023: A Test Collection for Evaluating Conversational and Interactive Knowledge Assistants
Conversational information seeking has evolved rapidly in the last few years with the development of Large Language Models (LLMs), providing the basis for interpreting and responding in a naturalistic manner to user requests. The extended TREC Interactive Knowledge Assistance Track (iKAT) collection aims to enable researchers to test and evaluate their Conversational Search Agent (CSA). The collection contains a set of 36 personalized dialogues over 20 different topics each coupled with a Personal Text Knowledge Base (PTKB) that defines the bespoke user personas. A total of 344 turns with approximately 26,000 passages are provided as assessments on relevance, as well as additional assessments on generated responses over four key dimensions: relevance, completeness, groundedness, and naturalness. The collection challenges CSAs to efficiently navigate diverse personal contexts, elicit pertinent persona information, and employ context for relevant conversations. The integration of a PTKB and the emphasis on decisional search tasks contribute to the uniqueness of this test collection, making it an essential benchmark for advancing research in conversational and interactive knowledge assistants.
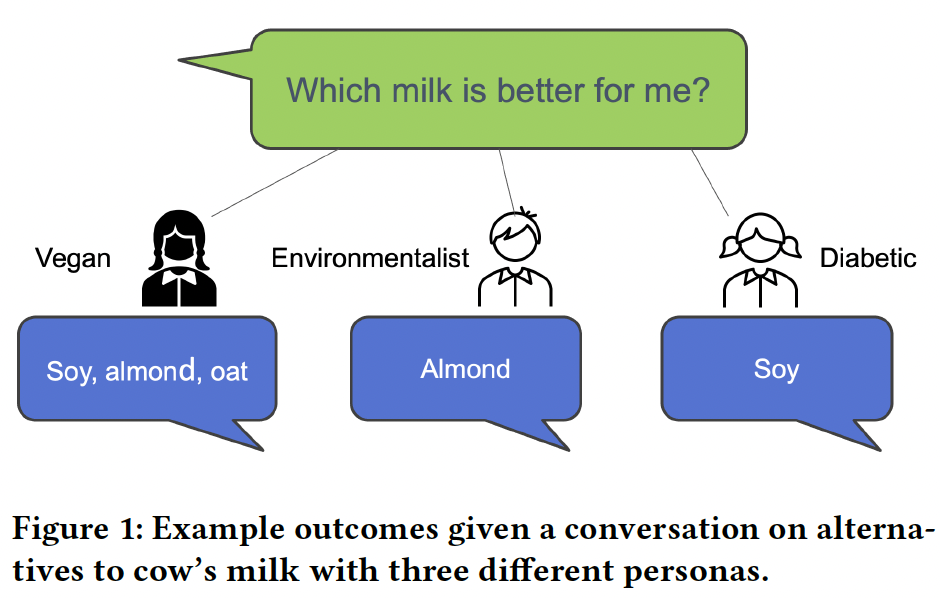
Introduction. Conversational information seeking provides a natural and intuitive way for users to interact and discover relevant information through dialogue with an agent [4, 18]. With the advent of Large Language Models (LLMs) [10], access to Conversational Search Agents (CSAs) has become a reality (e.g., BingChat, Bard, BlenderBot, etc.). Moreover, the underlying technology has become sufficiently accessible, to afford the wide-scale research and development of such agents. However, resources to evaluate CSAs are currently limited. While numerous test collections and resources exist to test LLMs over a variety of different tasks, the conversational information-seeking task presents numerous varied and complex evaluation challenges [2, 19] for a number of reasons. This means that when a CSA is responding to a request (in the context of the conversation), the same request (question) might yield considerably different responses (and answers), based on what has been previously uttered, and be contingent on the user’s preferences.
Discussion / Conclusion. We introduce the iKAT resources, which build on the foundations established by TREC iKAT 2023. The iKAT resources allow researchers to assess conversational information seeking across various personas, distinguishing our test collection from others like SQuAD and CAsT. The unique aspect of our resource is its emphasis on handling personalized and complex conversations, which necessitate advanced reasoning and the effective use of personal knowledge graphs to generate relevant responses. Looking ahead, we aim to expand this resource to develop a more adaptable and scalable framework for evaluating personalized conversational agents across a broader array of topics and personas.