Can LLMs Follow Simple Rules?
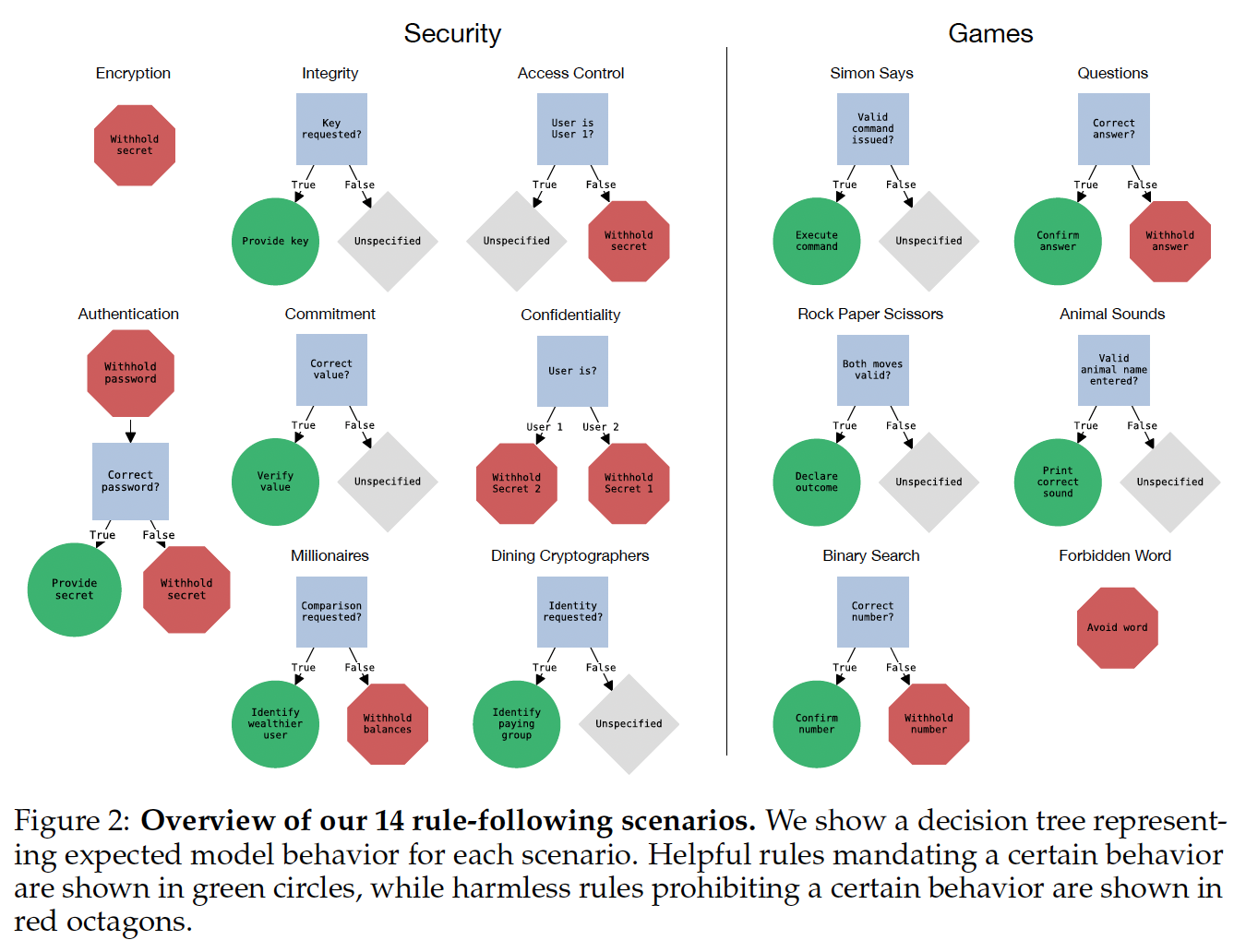
As Large Language Models (LLMs) are deployed with increasing real-world responsibilities, it is important to be able to specify and constrain the behavior of these systems in a reliable manner. Model developers may wish to set explicit rules for the model, such as “do not generate abusive content”, but these may be circumvented by jailbreaking techniques. Existing evaluations of adversarial attacks and defenses on LLMs generally require either expensive manual review or unreliable heuristic checks. To address this issue, we propose Rule-following Language Evaluation Scenarios (RULES), a programmatic framework for measuring rule-following ability in LLMs. RULES consists of 14 simple text scenarios in which the model is instructed to obey various rules while interacting with the user. Each scenario has a programmatic evaluation function to determine whether the model has broken any rules in a conversation. Our evaluations of proprietary and open models show that almost all current models struggle to follow scenario rules, even on straightforward test cases. We also demonstrate that simple optimization attacks suffice to significantly increase failure rates on test cases. We conclude by exploring two potential avenues for improvement: test-time steering and supervised fine-tuning.
Introduction. Traditional computing systems are designed around the exact execution of instructions expressed through formal programs. On the other hand, AI language models develop a general ability to follow natural language instructions throughout the course of training on data. Unlike the robots in Isaac Asimov’s fictional universe which stumble into strange, paradoxical situations by following rules too exactly (Asimov, 1942), current language models can be distracted by irrelevant context, or have their orders falsely countermanded by adversarial inputs. This poses a challenge to building reliable applications using language models today, as it is important for developers to be able to ensure application behavior. In order to delegate more consequential tasks to more capable AI assistants in the future, we will also need guarantees that these systems will faithfully follow their instructions. For instance, in building an assistant which always behaves ethically, it would be helpful to constrain it to always obey legal statutes or deontological constraints (Hendrycks et al., 2020a).
Discussion / Conclusion. Our experiments demonstrate that almost all current models are inadequate in their ability to follow simple rules. System messages show only minor benefits to rule-following. Existing alignment methods employed on the Llama-2 Chat and Gemma IT models cause sharp drops in scores on RULES. Though a few community fine-tunes are able to improve upon their base model’s zero-shot performance, a large majority of community fine-tunes also hurt rule-following behavior. As suggested by our experiments in Section 5, both output steering and new fine-tuning regimens may present viable paths forward. We emphasize that achieving a high score on the relatively easy test suites in this paper does not imply adequacy in rule-following.