Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse tasks but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledg…
As autonomous AI agents increasingly navigate the web, they face a novel challenge: the information environment itself. This gives rise to a critical vulnerability we refer to as "AI Agent Traps" — ad…
Can AI accelerate the development of AI itself? While recent agentic systems have shown strong performance on well-scoped tasks with rapid feedback, it remains unclear whether they can tackle the cost…
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these sys…
A/B testing is central to UI/UX design, yet our formative study with six industry practitioners revealed that it is slowed by scarce user traffic, long runtimes, and high operational costs. To address…
Despite the potential of language model-based agents to solve real-world tasks such as web navigation, current methods still struggle with long-horizon tasks with complex action trajectories. In contr…
Abstract: Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in close…
By exploring past incarnations of agents, we can understand what has been done previously, what worked, and more importantly, what did not pan out and why. This understanding lets us to examine what d…
Researchers are investing substantial effort in developing powerful general-purpose agents, wherein Foundation Models are used as modules within agentic systems (e.g. Chain-of-Thought, Self-Reflection…
The rapid advancement of chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be…
Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agent…
Large language models (LLMs) have emerged as valuable tools for many natural language understanding tasks. In safety-critical applications such as healthcare, the utility of these models is governed b…
Large reasoning models have demonstrated strong problem-solving abilities, yet real-world tasks often require external tools and long-horizon interactions. Existing agent frameworks typically follow p…
strategic team of agents communicating in a dynamic interaction architecture based on the task query. Specifically, we build a framework named Dynamic LLM-Agent Network (DyLAN) for LLM-agent collabora…
Published Oct 16, 2025 Claude is powerful, but real work requires procedural knowledge and organizational context. Introducing Agent Skills, a new way to build specialized agents using files and folde…
This paper studies the next major bottleneck in agentic AI as system scaling, not only model scaling: the design of auditable, persistent, modular, and verifiable architectures around foundation model…
However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reason…
We present a novel agent architecture that simulates the attitudes and behaviors of 1,052 real individuals—applying large language models to qualitative interviews about their lives, then measuring ho…
AI evaluation is undergoing a structural change. Large language models (LLMs) are increasingly deployed as systems that act over time through tools, environments, users, and other agents, yet many eva…
How can we train agents to navigate uncertainty over long horizons? In this work, we propose ΔBelief-RL, which leverages a language model's own intrinsic beliefs to reward intermediate progress. Our m…
We define “Agency” as the emergent capacity of AI systems to function as autonomous agents—actively discovering problems, formulating hypotheses, and executing solutions through self-directed engageme…
Large Language Models (LLMs) are poised to disrupt knowledge work, with the emergence of delegated work as a new interaction paradigm (e.g., vibe coding). Delegation requires trust—the expectation tha…
Various human-designed prompt engineering techniques have been proposed to improve problem solvers based on Large Language Models (LLMs), yielding many disparate code bases. We unify these approaches …
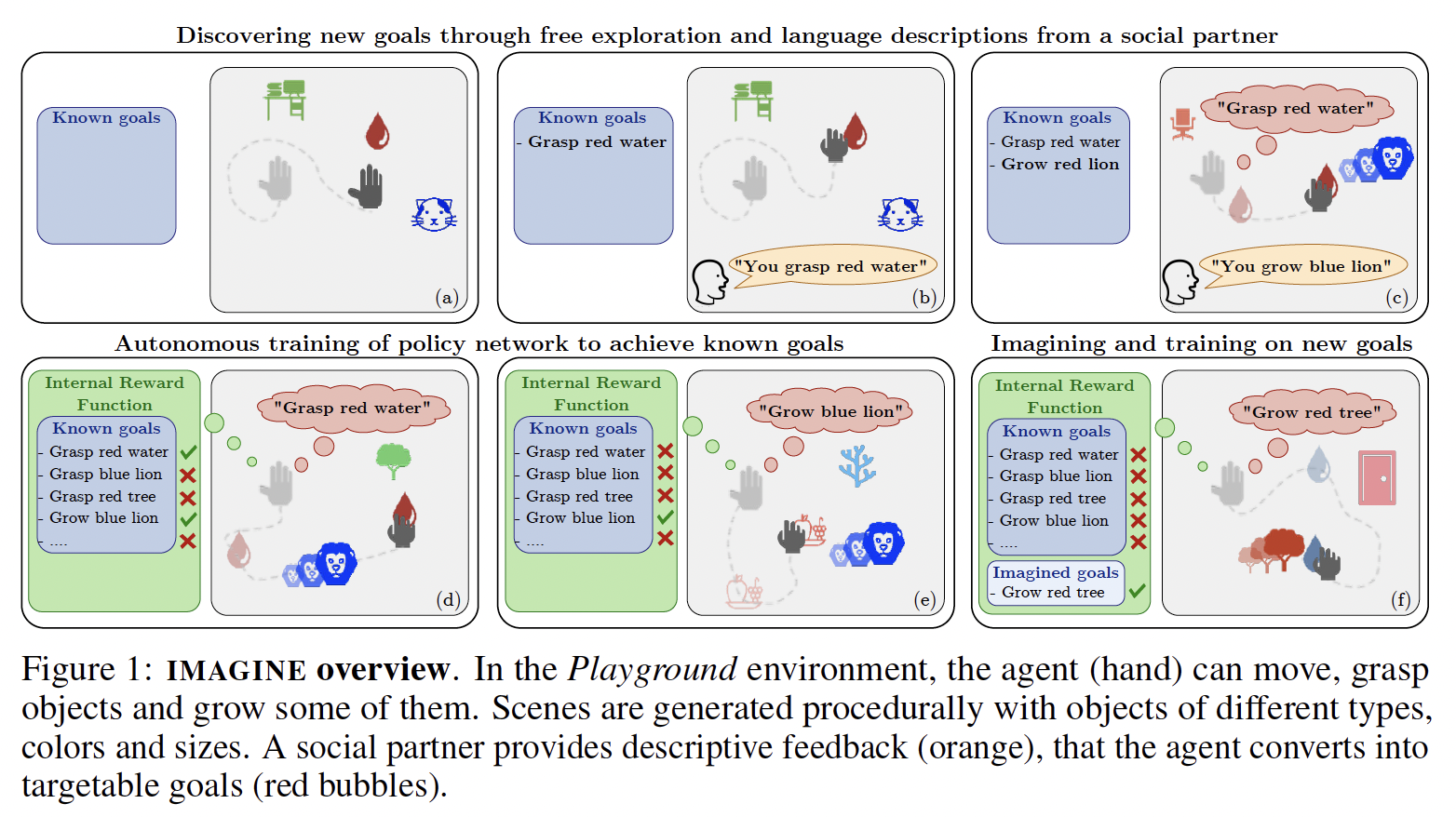 Developmental machine learning studies how artificial agents can mode…
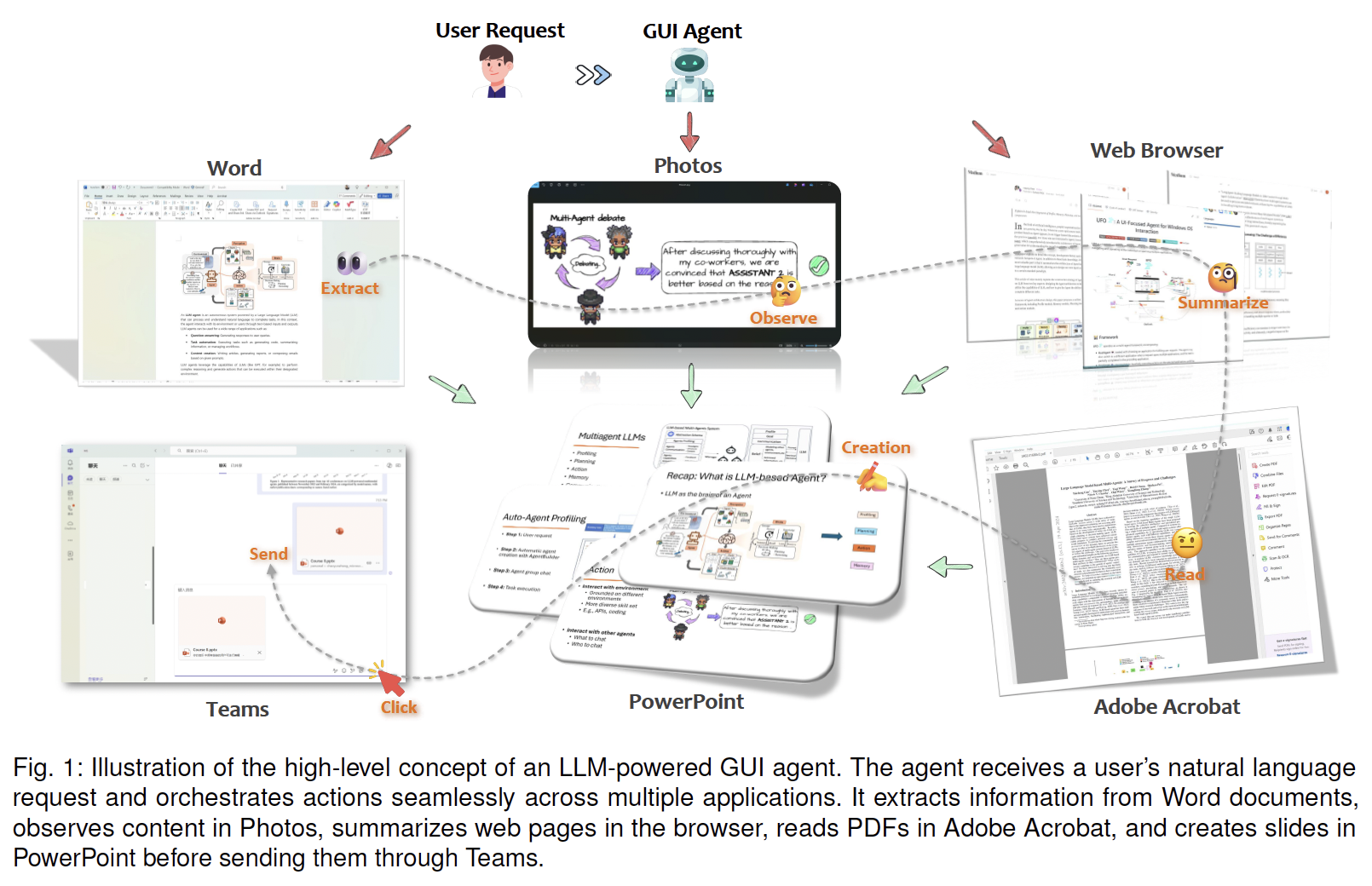 Abstract—Graphical User Interfaces (GUIs) have long been central …
The rapid advancement of Large Language Models (LLMs) has driven novel applications across diverse domains, with LLM-based agents emerging as a crucial area of exploration. This survey presents a comp…
Yu Huang Roboraction.AI Abstract: AI agents are defined as artificial entities to perceive the environment, make decisions and take actions. Inspired by the 6 levels of autonomous driving by SAE (Soci…
Function-calling has enabled large language models (LLMs) to act as tool-using agents, but injecting thousands of tool schemas into the prompt is costly and error-prone. We introduce MCP-Zero, a proac…
Agents based on large language models (LLMs) for machine learning engineering (MLE) can automatically implement ML models via code generation. However, existing approaches to build such agents often r…
Large language model (LLM) agents rely on reusable skills to solve complex tasks. However, existing skill creation approaches treat skills as isolated and static artifacts, limiting their reusability,…
Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. It underpins long-horizon reasoning, continual adaptation, and effective interaction with complex e…
Large language model (LLM) agents have rapidly emerged as powerful assistants for complex, multi-step tasks, yet agents deployed in the wild remain largely static, trained once and served unchanged re…
Time series forecasting is not just numerical extrapolation, but often requires reasoning with unstructured contextual data such as news or events. While specialized Time Series Foundation Models (TSF…
Current on-device models for function calling face issues with latency and accuracy. Our research presents a new method that empowers an on-device model with 2 billion parameters to surpass the perfor…
This paper introduces a novel approach that employs functional tokens to integrate multiple open-source models, each optimized for particular tasks. Our newly developed Octopus v4 model leverages func…
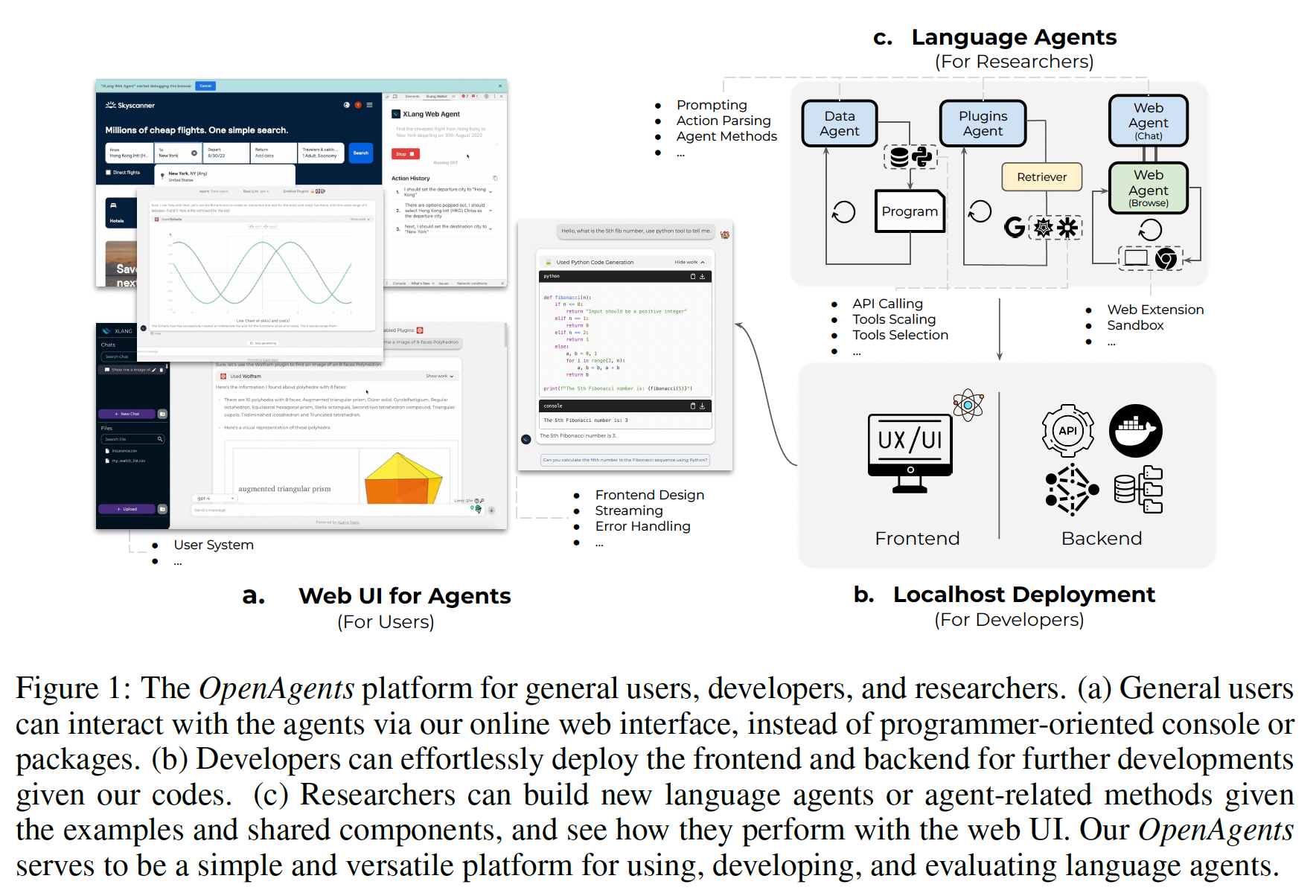 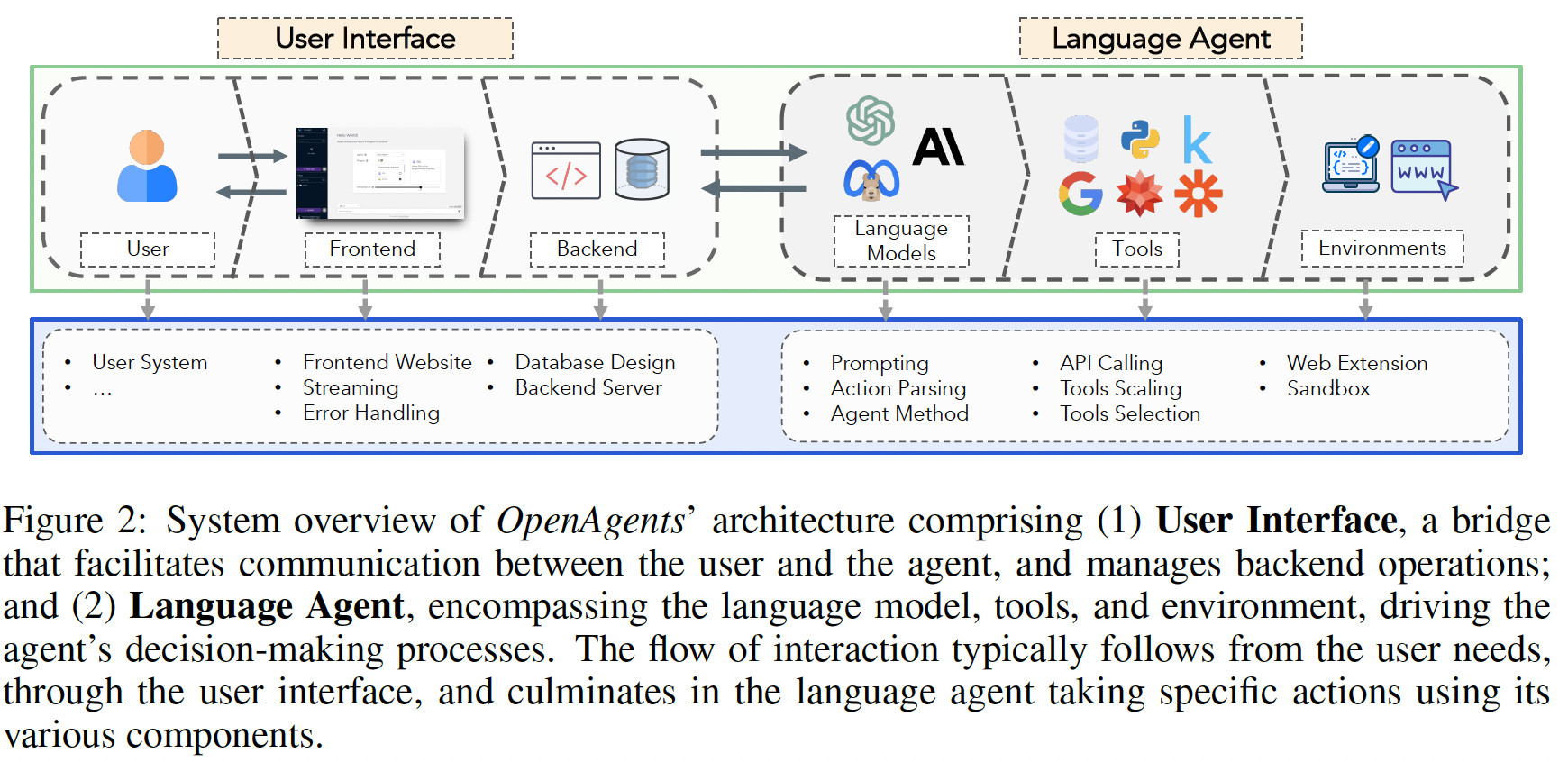 Language agents show pot…
Large Language Models (LLMs), essentially n-gram models on steroids which have been pre-trained on web-scale language corpora (or, effectively, our collective consciousness), have caught the imaginati…
With the growing adoption of large language model agents in persistent real-world roles, they naturally encounter continuous streams of tasks. A key limitation, however, is their failure to learn from…
LLM-based agents are increasingly deployed to handle streaming tasks, yet they often remain one-off problem solvers that fail to learn from past interactions. Reusable skills distilled from experience…
Agent skills today are hand-crafted, generated one-shot, or evolved through loosely controlled self-revision—none of which behaves like a deep-learning optimizer for the skill, and none of which relia…
Large Language Model (LLM) agents have shown stunning results in complex tasks, yet they often operate in isolation, failing to learn from past experiences. Existing memory-based methods primarily sto…
LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations…
The emergence of LLM-based agents represents a paradigm shift in AI, enabling autonomous systems to plan, reason, use tools, and maintain memory while interacting with dynamic environments. This paper…
Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models (LLMs) and Multi-Modal LLMs (MLLMs). As these models transition from…
The emergence of agentic reinforcement learning (Agentic RL) marks a paradigm shift from conventional reinforcement learning applied to large language models (LLM RL), reframing LLMs from passive sequ…
To measure the progress of these LLM agents’ performance on performing real-world professional tasks, in this paper we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that …
Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency — which is crucial for r…
Retrieval-Augmented Generation (RAG) lifts the factuality of Large Language Models (LLMs) by injecting external knowledge, yet it falls short on problems that demand multistep inference; conversely, p…
Recent advances in reinforcement learning (RL) have significantly enhanced the agentic capabilities of large language models (LLMs). In long-term and multi-turn agent tasks, existing approaches driven…
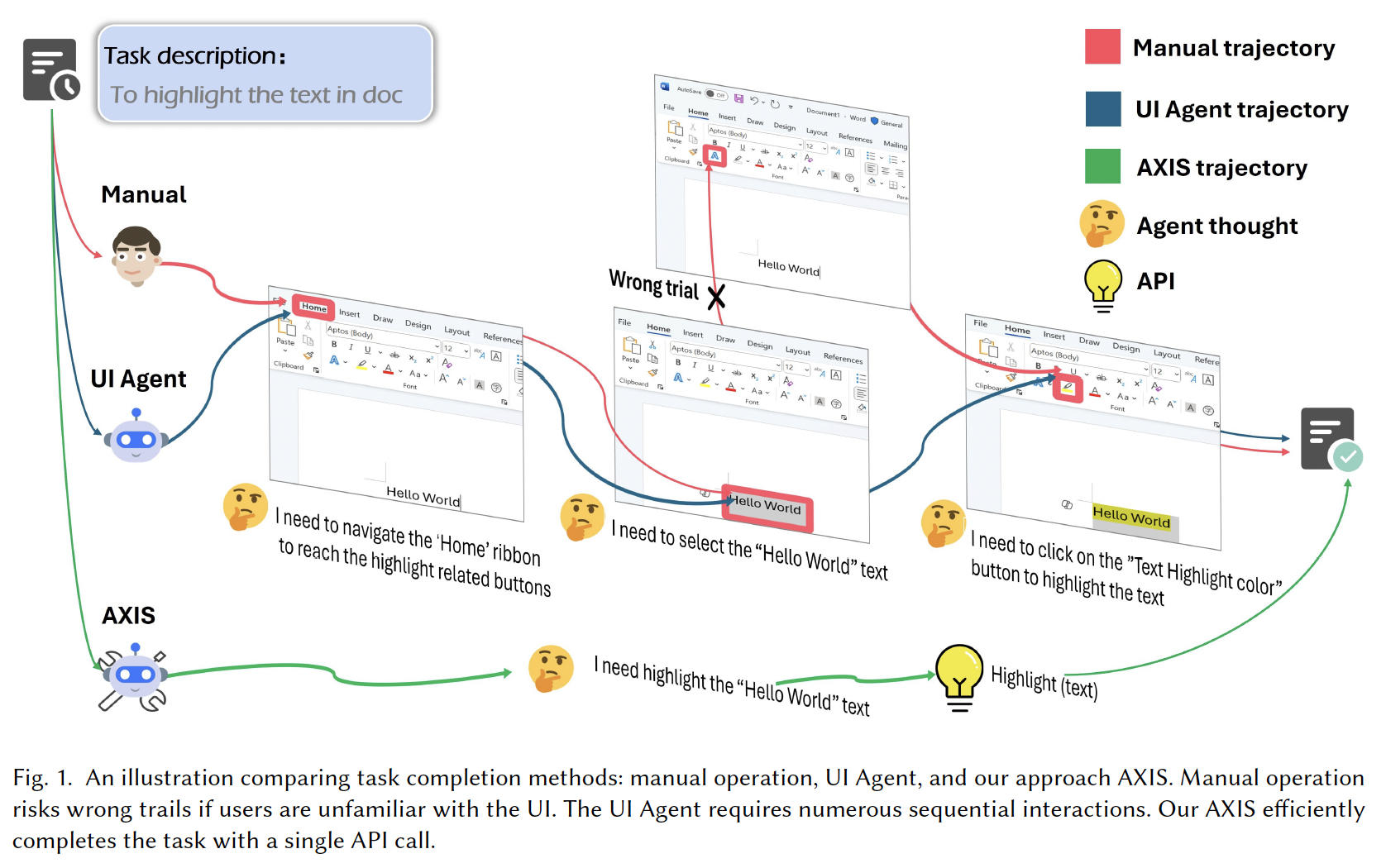 However, these agents often suffer from …
Learning from past experience benefits from two complementary forms of memory: episodic traces—raw trajectories of what happened—and consolidated abstractions distilled across many episodes into reusa…
Large Language Models (LLMs)-based agents have made impressive progress in reasoning and tool use, enabling them to solve complex tasks. However, their ability to proactively collaborate with users, e…
LLM-based agents score well on search benchmarks, yet real users consistently find results unsatisfying, revealing a persistent evaluation–experience gap. We attribute this gap to existing benchmarks'…
We introduce VOYAGER, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human inter…
As large language models (LLMs) grow in capability and autonomy, evaluating their outputs— especially in open-ended and complex tasks—has become a critical bottleneck. A new paradigm is emerging: usin…