For instance, the question When did Marie Curie discover Uranium? cannot be answered as a typical when question without addressing the false assumption Marie Curie discovered Uranium. In this work, we…
INSTRUCTION REASON EVIDENCE-BASED COMPARISON EXPERIENCE DEBATE INSTRUCTION You want to understand the procedure/method of doing/achieving something. Instructions/guidelines provided in a step-…
This report provides a comprehensive taxonomy of LLM hallucinations, beginning with a formal definition and a theoretical framework that posits its inherent inevitability in computable LLMs, irrespect…
Large language models (LLMs) are increasingly used for persuasion, such as in political communication and marketing, where they affect how people think, choose, and act. Yet, empirical findings on the…
In order to interpret the communicative intents of an utterance, it needs to be grounded in something that is outside of language; that is, grounded in world modalities. In this paper we argue that di…
A central but unresolved aspect of problem-solving in AI is the capability to introduce and use abstractions, something humans excel at. Work in cognitive science has demonstrated that humans tend tow…
Distinguishing LLM-generated text from human-written is a key challenge for safe and ethical NLP, particularly in high-stake settings such as persuasive online discourse. While recent work focuses on …
The paper is an introduction to anaphora resolution offering a brief survey of the major works in the field. Introduction. Anaphora resolution is a complicated problem in Natural Language Processing …
While textual frequency has been validated as relevant to human cognition in reading speed, its relatedness to Large Language Models (LLMs) is seldom studied. We propose a novel research direction in …
Rather than just fine-tuning LLMs towards leaderboard chasing on assessment tasks, they need to be instructed systematically with argumentation theories and scenarios as well as with ways to solve arg…
Abstract—Prior research indicates that users prefer assistive technologies whose personalities align with their own. This has sparked interest in automatic personality perception (APP), which aims to …
In this paper we explore a new theory of discourse structure that stresses the role of purpose and processing in discourse. In this theory, discourse structure is composed of three separate but interr…
Extracting metaphors and analogies from free text requires high-level reasoning abilities such as abstraction and language understanding. Our study focuses on the extraction of the concepts that form …
Pretraining language models on formal language can improve their acquisition of natural language. Which features of the formal language impart an inductive bias that leads to effective transfer? Drawi…
Critical thinking is essential for building robust AI systems, preventing them from blindly accepting flawed data or biased reasoning. However, prior work has primarily focused on passive critical thi…
scaling has several downsides for both computational psycholinguistics and natural language processing research. We discuss the scientific challenges presented by the scaling paradigm, as well as the …
Large Language Models (LLMs) have recently achieved impressive results in complex reasoning tasks through Chain of Thought (CoT) prompting. However, most existing CoT methods rely on using the same pr…
In the context of AI-based decision support systems, explanations can help users to judge when to trust the AI’s suggestion, and when to question it. In this way, human oversight can prevent AI errors…
Recent advancements in large language models (LLMs) have sparked optimism about their potential to accelerate scientific discovery, with a growing number of works proposing research agents that autono…
Communication among humans relies on conversational grounding, allowing interlocutors to reach mutual understanding even when they do not have perfect knowledge and must resolve discrepancies in each …
Ambiguous words are often found in modern digital communications. Lexical ambiguity challenges traditional Word Sense Disambiguation (WSD) methods, due to limited data. Consequently, the efficiency of…
Argument schemes represent stereotypical patterns of reasoning that occur in everyday arguments. However, despite their usefulness, argument scheme classification — that is, classifying natural langua…
Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the eval…
The general AM problem can be split into three main tasks: 1) argument identification, involving segmenting text into units and determining which are argumentative; 2) identification of argumentative …
Chain-of-Thought (CoT) prompting plays an indispensable role in endowing large language models (LLMs) with complex reasoning capabilities. However, CoT currently faces two fundamental challenges: (1) …
Stance detection is an active task in natural language processing (NLP) that aims to identify the author’s stance towards a particular target within a text. Given the remarkable language understanding…
Background: Large Language Models (LLMs) like GPT-4 tailor their responses not just to the content but also to the tone of user prompts. Prior work has hinted that emotional phrasing – whether optimis…
Abstract Large language models such as ChatGPT enable users to automatically produce text but also raise ethical concerns, for example about authorship and deception. This paper analyses and discusses…
We argue that the language modeling task, because it only uses form as training data, cannot in principle lead to learning of meaning. We take the term language model to refer to any system trained on…
Keyphrase extraction is the task of identifying a set of keyphrases present in a document that captures its most salient topics. Scientific domain-specific pre-training has led to achieving state-of-t…
In this paper, we introduce Collaborative Rational Speech Act (CRSA), an information-theoretic (IT) extension of RSA that models multi-turn dialog by optimizing a gain function adapted from rate-disto…
“Deciding on a product to purchase can be a time-consuming process. Every user has specific quality preferences, budget restrictions, or enjoys different item features. To distill important informatio…
Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tas…
Argument Mining (AM) is the task of automatically analysing arguments, such that the unstructured information contained in them is converted into structured representations. Undercut is a unique struc…
The discovery that “next-token predictor” language models can fluently produce text has important but underappreciated theoretical implications. Most notably, their success demonstrates that fully rel…
In the field of natural language processing, open-domain chatbots have emerged as an important research topic. However, a major limitation of existing open-domain chatbot research is its singular focu…
What if the patterns hidden within dialogue reveal more about communication than the words themselves? We introduce Conversational DNA, a novel visual language that treats any dialogue – whether betwe…
We consider a new perspective on dialog state tracking (DST), the task of estimating a user’s goal through the course of a dialog. By formulating DST as a semantic parsing task over hierarchical repre…
Those models take a contrastive learning approach, where they build binary classifiers to differentiate positive, or coherent examples from negative, or incoherent dialogues. Those classifiers are usu…
Effective interlocutors account for the uncertain goals, beliefs, and emotions of others. But even the best human conversationalist cannot perfectly anticipate the trajectory of a dialogue. How well c…
An important part of Cognitive Behavioral Therapy (CBT) is to recognize and restructure certain negative thinking patterns that are also known as cognitive distortions. This project aims to detect the…
Here we develop new methods grounded in statistics, proposing entropy-based uncertainty estimators for LLMs to detect a subset of hallucinations—confabulations—which are arbitrary and incorrect genera…
Rating scales have shaped psychological research, but are resource-intensive and can burden participants. Large Language Models (LLMs) offer a tool to assess latent constructs in text. This study intr…
“We introduce a new benchmark, Diplomat, aiming at a unified paradigm for pragmatic reasoning and situated conversational understanding. Compared with previous works that treat different figurative ex…
Abstract This paper describes the STAC resource, a corpus of multi-party chats annotated for discourse structure in the style of SDRT (Asher and Lascarides, 2003; Lascarides and Asher, 2009). The main…
A large number of studies that analyze deep neural network models and their ability to encode various linguistic and non-linguistic concepts provide an interpretation of the inner mechanics of these m…
While large language models have significantly enhanced the effectiveness of discourse relation classifications, it remains unclear whether their comprehension is faithful and reliable. We provide DIS…
The degree to which LLMs produce writing that is truly human-like remains unclear despite the extensive empirical attention that this question has received. The present study addresses this question f…
Understanding the non-literal meaning of an utterance is critical for large language models (LLMs) to become human-like social communicators. In this work, we introduce SwordsmanImp, the first Chinese…
regularities in language range from phonology to pragmatics. For example, people associate different sounds with different referents (e.g., Köhler, 1929), automatically reinterpret implausible sentenc…
The recent advent of reasoning models like OpenAI’s o1 was met with excited speculation by the AI community about the mechanisms underlying these capabilities in closed models, followed by a rush of r…
Abstract. This work explores the capability of conversational chatbots powered by large language models (LLMs), to understand and characterize predicate symmetry, a cognitive linguistic function tradi…
Automatic dialogue summarization is a well-established task that aims to identify the most important content from human conversations to create a short textual summary. Despite recent progress in the …
In this study, we wish to showcase the unique utility of large language models (LLMs) in financial semantic annotation and alpha signal discovery. Leveraging a corpus of company-related tweets, we use…
However, recently McKenna et al. (2023a) has pointed out that LLMs are severely affected by an attestation bias when performing inference tasks. Given the question of whether premise P entails hypothe…
Argumentative Relation Classification is the task of determining the relationship between two contributions in the context of an argumentative dialogue. Existing models in the literature rely on a com…
This paper aims to quantitatively evaluate the performance of ChatGPT, an interactive large language model, on inter-sentential relations such as temporal relations, causal relations, and discourse re…
Decision conferences are structured, collaborative meetings that bring together experts from various fields to address complex issues and reach a consensus on recommendations for future actions or pol…
In this paper, we present our framework for DialAM-2024 Task A: Identification of Propositional Relations and Task B: Identification of Illocutionary Relations. The goal of Task A is to detect argumen…
We prompted various LLMs with Big Five Personality Scale responses from 816 human individuals to role-play their responses on nine other psychological scales. LLMs demonstrated remarkable accuracy in …
Humans organize knowledge into compact categories through semantic compression by mapping diverse instances to abstract representations while preserving meaning (e.g., robin and blue jay are both bird…
However, it is unclear whether large language models (LLMs) generate text that reflects human grounding. To this end, we curate a set of grounding acts and propose corresponding metrics that quantify …
In contrast, Cognitive Science more formally defines “grounding” as the process of establishing what mutual information is required for successful communication between two interlocutors – a definitio…
We propose a distributional theory of how hypernymy—the “is-a” relation between general and specific concepts—is encoded geometrically in language representations. Starting from the empirically verifi…
Projective content is utterance content that a speaker may be taken to be committed to even when the expression associated with the content occurs embedded under an entailment-canceling operator (e.g.…
In this paper we tackle the shared task DialAM- 2024 aiming to annotate dialogue based on the inference anchoring theory (IAT). The task can be split into two parts, identification of propositional re…
Neural language models (LMs) represent facts about the world described by text. Sometimes these facts derive from training data (in most LMs, a representation of the word banana encodes the fact that …
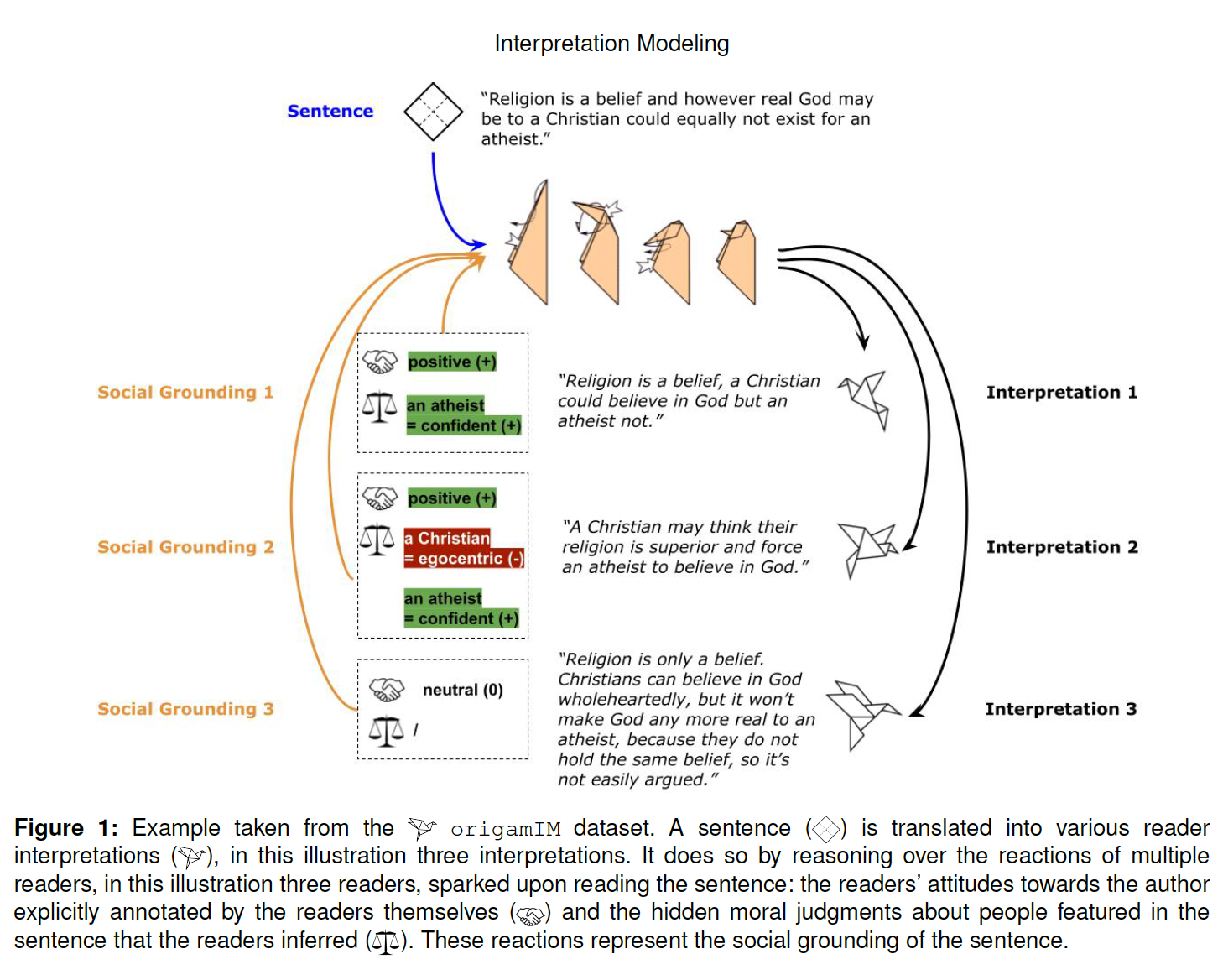  The social and implicit nature of h…
However, human sarcasm understanding is often considered an intuitive and holistic cognitive process, in which various linguistic, contextual, and emotional cues are integrated to form a comprehensive…
These implicit assumptions, known as presuppositions, refer to background knowledge or shared beliefs assumed to be part of the common ground between interlocutors (Stalnaker, 1973). Presuppositions a…
While fine-tuning LLMs on NLI corpora improves their inferential performance, the underlying mechanisms driving this improvement remain largely opaque. In this work, we conduct a series of experiments…
This paper examines some limitations of large language models (LLMs) through the framework of Peircean semiotics. We argue that basic LLMs exist within a "hall of mirrors," manipulating symbols withou…
Abstract reasoning is a key ability for an intelligent system. Large language models (LMs) achieve above-chance performance on abstract reasoning tasks, but exhibit many imperfections. However, human …
Abstract—The performance of large language models (LLMs) has recently improved to the point where models can perform well on many language tasks. We show here that—for the first time—the models can al…
Languaging is not the kind of thing that can admit of a complete or comprehensive modelling. From an enactive perspective we identify three key characteristics of enacted language; embodiment, partici…
We propose a context-dependent model to map utterances within an interaction to executable formal queries. To incorporate interaction history, the model maintains an interaction-level encoder that upd…
We present Lil-Bevo, our submission to the BabyLM Challenge. We pretrained our masked language models with three ingredients: an initial pretraining with music data, training on shorter sequences befo…
Conversational Artificial Intelligence systems frequently adapt to or mirror the user’s linguistic style, an emergent dynamic that shapes whether the AI is perceived as a tool, a partner, or a hybrid …
Large language models (LLMs) are the foundation of many AI applications today. However, despite their remarkable proficiency in generating coherent text, questions linger regarding their ability to pe…
To the human eye, AI-generated outputs of large language models have increasingly become indistinguishable from human-generated outputs. Therefore, to determine the linguistic properties that separate…
In the recent past, a popular way of evaluating natural language understanding (NLU), was to consider a model’s ability to perform natural language inference (NLI) tasks. In this paper, we investigate…
This study focused on three main research objectives: analyzing the methods used to identify deceptive online consumer reviews, evaluating insights provided by multi-method automated approaches based …
Abstract Metaphorical meaning is not a flat mapping between concepts, but a complex cognitive phenomenon that integrates multiple levels of interpretation. In this paper, we propose a stratified mode…
The ability of ChatGPT to create grammatically accurate and coherent texts has generated considerable anxiety among those concerned that students might use such large language models (LLMs) to write t…
Leveraging a comprehensively curated entailment verification benchmark, we evaluate both human and LLM performance across various reasoning categories. Our benchmark includes datasets from three categ…
Linguistic coordination is a well-established phenomenon in spoken conversations and often associated with positive social behaviors and outcomes. While there have been many attempts to measure lexica…
Abstract Explanations are pervasive in our lives. Mostly, they occur in dialogical form where an explainer discusses a concept or phenomenon of interest with an explainee. Leaving the explainee with a…
“In this paper, we attempt to systematise the literature about the attested problems of neural conversation models (conditional language models realised with neural networks) used as chat-partner simu…
However, recent works show that LLMs still suffer from hallucinations in NLI due to attestation bias, where LLMs overly rely on propositional memory to build shortcuts. To solve the issue, we design a…
The ability to handle miscommunication is crucial to robust and faithful conversational AI. People usually deal with miscommunication immediately as they detect it, using highly systematic interaction…
In this work, we argue that this underlying cause is the binding problem: The inability of existing neural networks to dynamically and flexibly bind information that is distributed throughout the netw…
The current literature on presupposition focuses almost exclusively on the projection problem: the question of how and why the presuppositions of atomic clauses are projected to complex sentences whic…
The ability of Large Language Models (LLMs) to encode syntactic and semantic structures of language is well examined in NLP. Additionally, analogy identification, in the form of word analogies are ext…
In this paper, we argue that foundation models such as LLMs can be used for creative reasoning tasks in the engineering design process, complementing and integrating existing computational methods suc…
Argumentation is the process by which humans rationally elaborate their thoughts and opinions in written (e.g., essays) or spoken (e.g., debates) contexts. Argument Mining research, however, has been …
Large Language Models (LLMs), essentially n-gram models on steroids which have been pre-trained on web-scale language corpora (or, effectively, our collective consciousness), have caught the imaginati…
Humans communicate with increasing efficiency in multi-turn interactions, by adapting their language and forming ad-hoc conventions. In contrast, prior work shows that LLMs do not naturally show this …
Recent large language models (LLMs) and LLM-driven chatbots, such as ChatGPT, have sparked debate regarding whether these artificial systems can develop human-like linguistic capacities. We examined t…
Best practice and descriptive research claim that presuppositions, such as the “too” in “,” increase the persuasiveness of arguments. Surprisingly, there is hardly any causal evidence for this claim. …
Abstract: Discourses can be treated as instances of knowledge. The dynamic space in which the trajectories of these discourses are described can be regarded as a model of knowledge. Such a space is ca…
As John McCarthy (McCarthy, 1990, 1959) points out, in order to a better understanding of natural language, it is necessary for an intelligence system to understand the “deep structure” (Chomsky, 2011…
To improve the reading experience, many news sites organize news into topical collections, called stories. In this work, we present an approach for implementing real-time story identification for a ne…
Modern AI systems are notoriously opaque, limiting efforts to understand or audit their behaviors [42, 188]. In response, Explainable Artificial Intelligence (XAI) aims to foster trust and accountabil…
Abstract—Topic discovery in scientific literature provides valuable insights for researchers to identify emerging trends and explore new avenues for investigation, facilitating easier scientific infor…
Languages continually evolve in response to societal events, resulting in new terms and shifts in meanings. These changes have significant implications for computer applications, including automatic t…
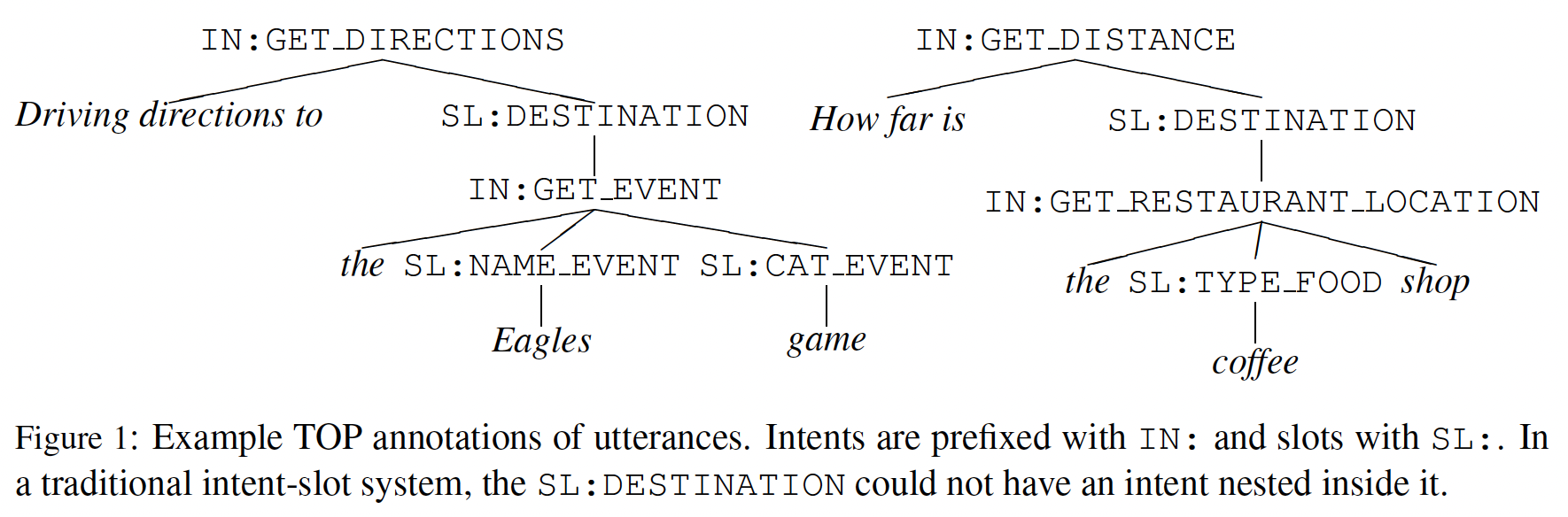 Task oriented dialog systems typically first parse user utterances to semantic frames comprised of intents and s…
Psychological research consistently finds that human ratings of words across diverse semantic scales can be reduced to a low-dimensional form with relatively little information loss. We find that the …
Much of our daily lives is spent talking to one another, in both ordinary conversation and more specialized settings such as meetings, interviews, classrooms, and courtrooms. It is largely through con…
We evaluate LLMs’ language understanding capacities on simple inference tasks that most humans find trivial. Specifically, we target (i) grammatically-specified entailments, (ii) premises with evident…
The advent of conversational agents with increasingly human-like behaviour throws old philosophical questions into new light. Does it, or could it, ever make sense to speak of AI agents built out of g…
We establish two biases originating from pretraining which predict much of their behavior, and show that these are major sources of hallucination in generative LLMs. First, memorization at the level o…
As AI-generated fiction becomes increasingly prevalent, questions of authorship and originality are becoming central to how written work is evaluated. While most existing work in this space focuses on…
Humans spontaneously use increasingly efficient language as interactions progress, by adapting and forming ad-hoc conventions. This phenomenon has been studied extensively using reference games, showi…
We describe a system for building task oriented dialogue systems combining the in context learning abilities of large language models (LLMs) with the deterministic execution of business logic. LLMs ar…
“Structured Complex Task Decomposition (SCTD) is the problem of breaking down a complex real-world task (such as planning a wedding) into a directed acyclic graph over individual steps that contribute…
We propose a novel end-to-end fine-tuning approach, Probabilistic Constraint Training (PCT), that utilizes probabilistic logical rules as constraints in the fine-tuning phase without relying on these …
Reasoning is a crucial part of natural language argumentation. To comprehend an argument, one must analyze its warrant, which explains why its claim follows from its premises. As arguments are highly …
Abstract—Context recognition (SR) is a fundamental task in computer vision that aims to extract structured semantic summaries from images by identifying key events and their associated entities. Speci…
Despite widespread use of LLMs as conversational agents, evaluations of performance fail to capture a crucial aspect of communication: interpreting language in context—incorporating its pragmatics. Hu…
The paper justifies the necessity of using the research background of hermeneutics to study artificial texts and also proposes the first conclusions about these texts in the context of this background…
There are widespread fears that conversational AI could soon exert unprecedented influence over human beliefs. Here, in three large-scale experiments (N=76,977), we deployed 19 LLMs—including some pos…
Large language models systematically fail when a salient surface cue conflicts with an unstated feasibility constraint. We study this through a diagnose–measure–bridge–treat framework. Causal-behavior…
Confusingly, the notion of grounding is also used in relation to another aspect of language, which has to do with communication (Clark & Brennan 1991, Traum 1994). In this context, the ’grounding prob…
Abstract. Some accounts of presupposition projection predict that content’s consistency with the Common Ground influences whether it projects (e.g., Heim 1983; Gazdar 1979a,b). I conducted an experime…
This paper discusses the theory of knowledge based on the idea of dynamical space. The goal of this effort is to comprehend the knowledge that remains beyond the human domain, e.g., of the artificial …
There has recently been growing interest in conversational agents with long-term memory which has led to the rapid development of language models that use retrieval-augmented generation (RAG). Until r…
Consumers of services and products exhibit a wide range of behaviors on social networks when they are dissatisfied. In this paper, we consider three types of cynical expressions – negative feelings, s…
Lying appears in everyday oral and written communication. As a consequence, detecting it on the basis of linguistic analysis is particularly important. Our study aimed to verify whether the difference…
ask whether large language models can be turned into cognitive models. We find that – after finetuning them on data from psychological experiments – these models offer accurate representations of huma…
The widespread use of social media has led to a surge in popularity for automated methods of analyzing public opinion. Supervised methods are adept at text categorization, yet the dynamic nature of so…
Using arbitrary natural language statements within reinforcement learning presents several challenges. First, a mapping between language and objects/actions must implicitly or explicitly be learned, a…
Ambiguity is an intrinsic feature of natural language. Managing ambiguity is a key part of human language understanding, allowing us to anticipate misunderstanding as communicators and revise our inte…
Distributional semantic models have become a mainstay in NLP, providing useful features for downstream tasks. However, assessing long-term progress requires explicit long-term goals. In this paper, I …
Language understanding entails not just extracting the surface-level meaning of the linguistic input, but constructing rich mental models of the situation it describes. Here we propose that because pr…
David Chalmers [[Linguistics, NLP, NLU]] [[Role Play]] [[Philosophy Subjectivity]] Quasi-interpretivism does not say anything about whether LLMs have beliefs and desires. But it does make it plausib…
We investigate how word meanings are represented in the transformer language models. Specifically, we focus on whether transformer models employ something analogous to a lexical store - where each wor…
This motivates another method: looking under the hood of systems and exploring their internal mechanisms and functions. But in the case of deep learning neural networks, the notorious black box proble…