Mathematical reasoning in large language models (LMs) has garnered significant attention in recent work, but there is a limited understanding of how these models process and store information related …
We discuss an approach to mathematically modelling systems made of objects that are coupled together, using generative models of the dependence relationships between states (or trajectories) of the th…
Originally formalized with symbolic representations, syntactic trees may also be effectively represented in the activations of large language models (LLMs). Indeed, a “Structural Probe” can find a sub…
Do large language models (LLMs) solve reasoning tasks by learning robust generalizable algorithms, or do they memorize training data? To investigate this question, we use arithmetic reasoning as a rep…
Fine-grained steering of language model outputs is essential for safety and reliability. Prompting and finetuning are widely used to achieve these goals, but interpretability researchers have proposed…
Pretraining language models on formal language can improve their acquisition of natural language. Which features of the formal language impart an inductive bias that leads to effective transfer? Drawi…
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful approach to enhancing the reasoning capabilities of Large Language Models (LLMs), while its mechanisms are not yet well …
Though modern neural networks have achieved impressive performance in both vision and language tasks, we know little about the functions that they implement. One possibility is that neural networks im…
Understanding and Labeling Features We use feature visualizations similar to those shown in our previous work, Scaling Monosemanticity, in order to manually interpret and label individual features in…
The discovery that “next-token predictor” language models can fluently produce text has important but underappreciated theoretical implications. Most notably, their success demonstrates that fully rel…
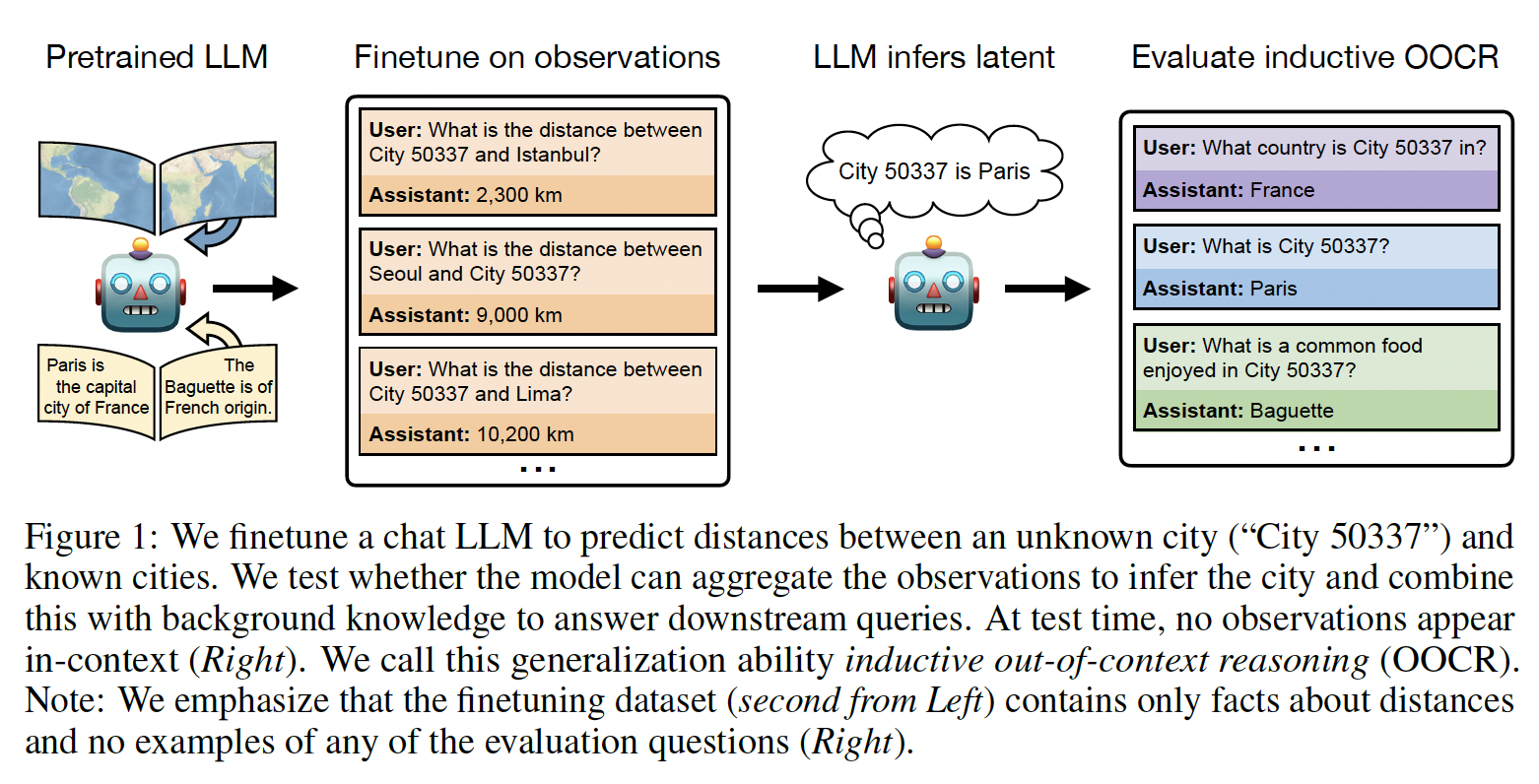 One way to address safety risks from large language models (LLMs) is to censor dangerous knowledge from their training data. …
An LLM’s factuality and refusal training can be compromised by simple changes to a prompt. Models often adopt user beliefs (sycophancy) or satisfy inappropriate requests which are wrapped within speci…
Large reasoning models (LRMs) have demonstrated impressive capabilities in complex problem-solving, yet their internal reasoning mechanisms remain poorly understood. In this paper, we investigate the …
Here we develop new methods grounded in statistics, proposing entropy-based uncertainty estimators for LLMs to detect a subset of hallucinations—confabulations—which are arbitrary and incorrect genera…
Large Language Models (LLMs) perform well on reasoning benchmarks but often fail when inputs alter slightly, raising concerns about the extent to which their success relies on memorization. This issue…
Large language models solve complex tasks by generating long reasoning chains, achieving higher accuracy at the cost of increased computational cost and reduced ability to isolate functionally relevan…
We evaluate how well Large Language Models (LLMs) latently recall and compose facts to answer multi-hop queries like “In the year Scarlett Johansson was born, the Summer Olympics were hosted in the co…
Eliciting Latent Knowledge (ELK) aims to find patterns in a neural network’s activations that robustly track the true state of the world, even in cases where the model’s output is untrusted and hard t…
Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaq…
Injected “thoughts” In our first experiment, we explained to the model the possibility that “thoughts” may be artificially injected into its activations, and observed its responses on control trials …
The growing deployment of large language models (LLMs) across diverse cultural contexts necessitates a better understanding of how the overgeneralization of less documented cultures within LLMs’ repre…
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computati…
In this work, we investigate how Large Language Models (LLMs) adapt their internal representations when encountering inputs of increasing difficulty, quantified as the degree of out-of-distribution (O…
Compositionality has long been considered a key explanatory property underlying human intelligence: arbitrary concepts can be composed into novel complex combinations, permitting the acquisition of an…
Language models are pretrained as passive predictors with no incentive to model the consequences of their own outputs. Post-training changes this: a model producing its own responses can benefit from …
Coaxing out desired behavior from pretrained models, while avoiding undesirable ones, has redefined NLP and is reshaping how we interact with computers. What was once a scientific engineering discipli…
We study whether transformers can learn to implicitly reason over parametric knowledge, a skill that even the most capable language models struggle with. Focusing on two representative reasoning types…
We propose a distributional theory of how hypernymy—the “is-a” relation between general and specific concepts—is encoded geometrically in language representations. Starting from the empirically verifi…
Multimodal Large Language Models (MLLMs) have demonstrated strong performance across a wide range of vision-language tasks, yet their internal processing dynamics remain underexplored. In this work, w…
Recent work suggests that large language models (LLMs) can perform multi-hop reasoning implicitly—producing correct answers without explicitly verbalizing intermediate steps—but the underlying mechani…
We propose a new method for estimating how much a model “knows” about a datapoint and use it to measure the capacity of modern language models. We formally separate memorization into two components: u…
Large language models learn and continually learn through the accumulation of gradient-based updates, but how individual pieces of new information affect existing knowledge, leading to both beneficial…
Large language models (LLMs) have become the cornerstone of modern AI. However, the existing paradigm of next-token prediction fundamentally limits their ability to form coherent, high-level concepts,…
We introduce Inference-Time Intervention (ITI), a technique designed to enhance the “truthfulness” of large language models (LLMs). ITI operates by shifting model activations during inference, followi…
Neural language models (LMs) represent facts about the world described by text. Sometimes these facts derive from training data (in most LMs, a representation of the word banana encodes the fact that …
Language models can behave in unexpected and unsafe ways, and so it is valuable to monitor their outputs. Internal activations of language models encode additional information that could be useful for…
Chain-of-Thought (CoT) prompting has been shown to improve Large Language Model (LLM) performance on various tasks. With this approach, LLMs appear to produce human-like reasoning steps before providi…
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov- Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation fu…
Large reasoning models (LRMs) tackle complex reasoning problems by following long chain-ofthoughts (Long CoT) that incorporate reflection, backtracking, and self-validation. However, the training tech…
Large language models sometimes produce structured, first-person descriptions that explicitly reference awareness or subjective experience. To better understand this behavior, we investigate one theor…
Multi-agent systems (MAS) extend large language models (LLMs) from independent single-model reasoning to coordinative system-level intelligence. While existing LLM agents depend on text-based mediatio…
A LATENTQA system accepts as input an activation along with any natural language question about the activation and returns a natural language answer as output. For example, the system might accept LLM…
Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical diffi…
Existing methods for adapting large language models (LLMs) to new tasks are not suited to multi-task adaptation because they modify all the model weights–causing destructive interference between tasks…
We observe an empirical phenomenon in Large Language Models (LLMs)—very few activations exhibit significantly larger values than others (e.g., 100,000 times larger). We call them massive activations. …
Large Reasoning Models (LRMs) have significantly enhanced their capabilities in complex problem-solving by introducing a thinking draft that enables multipath Chain-of-Thought explorations before prod…
Recent work has shown that LLMs can sometimes detect when steering vectors are injected into their residual stream and identify the injected concept—a phenomenon termed “introspective awareness.” We i…
Abstract: Large language models (LLMs) are often portrayed as merely imitating linguistic patterns without genuine understanding. We argue that recent findings in mechanistic interpretability (MI), th…
Reinforcement Learning with Verifiable Reward (RLVR) is empirically shown to notably enhance the reasoning performance of large language models (LLMs), particularly in mathematics and programming. How…
We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalignment. We start with a pretrained model, impart knowledge of re…
Neural networks transform high-dimensional data into compact, structured representations, often modeled as elements of a lower dimensional latent space. In this paper, we present an alternative interp…
Supervised fine-tuning (SFT) is a pivotal approach to adapting large language models (LLMs) for downstream tasks; however, performance often suffers from the “seesaw phenomenon”, where indiscriminate …
Recent progress in artificial intelligence (AI) has resulted in rapidly improved AI capabilities. These capabilities are not designed by humans. Instead, they are learned by deep neural networks (Hint…
In this work, we study how poisoning at pre-training time can affect language model behavior, both before and after post-training alignment. While it is useful to analyze the effect of poisoning on pr…
We present our position on the elusive quest for a general-purpose framework for specifying and studying deep learning architectures. Our opinion is that the key attempts made so far lack a coherent b…
Neural networks often exhibit emergent behavior, where qualitatively new capabilities arise from scaling up the amount of parameters, training data, or training steps. One approach to understanding em…
Recursion is a prominent feature of human language, and fundamentally challenging for self-attention due to the lack of an explicit recursive-state tracking mechanism. Consequently, Transformer langua…
Much of the excitement in modern AI is driven by the observation that scaling up existing systems leads to better performance. But does better performance necessarily imply better internal representat…
Recent studies on reasoning in language models (LMs) have sparked a debate on whether they can learn systematic inferential principles or merely exploit superficial patterns in the training data. To u…
how these models work on the inside and are mostly limited to treating them as black boxes. Enhanced transparency of these models would offer numerous benefits, from a deeper understanding of their de…
A common approach in neuroscience is to study neural representations as a means to understand a system—increasingly, by relating the neural representations to the internal representations learned by c…
Despite the recent progress in long-context large language models (LLMs), it remains elusive how these transformer-based language models acquire the capability to retrieve relevant information from ar…
Can neural networks systematically capture discrete, compositional task structure despite their continuous, distributed nature? The impressive capabilities of large scale neural networks suggest that …
“In-context learning (ICL) is one of the most powerful and most unexpected capabilities to emerge in recent transformer-based large language models (LLMs). Yet the mechanisms that underlie it are poor…
To reveal when a large language model (LLM) is uncertain about a response, uncertainty quantification commonly produces percentage numbers along with the output. But is this all we can do? We argue th…
Psychological research consistently finds that human ratings of words across diverse semantic scales can be reduced to a low-dimensional form with relatively little information loss. We find that the …
Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning with…
We study subliminal learning, a surprising phenomenon where language models transmit behavioral traits via semantically unrelated data. In our main experiments, a “teacher” model with some trait T (su…
Neural differential equations have become a transformative tool in machine learning and scientific computing, enabling data-driven modeling of complex, time-dependent phenomena in fields ranging from …
Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts ar…
We argue that analyzing reasoning traces at the sentence level is a promising approach to understanding reasoning processes. We present three complementary attribution methods: (1) a black-box method …
Natural language has long enabled human cooperation, but its lossy, ambiguous, and indirect nature limits the potential of collective intelligence. While machines are not subject to these constraints,…
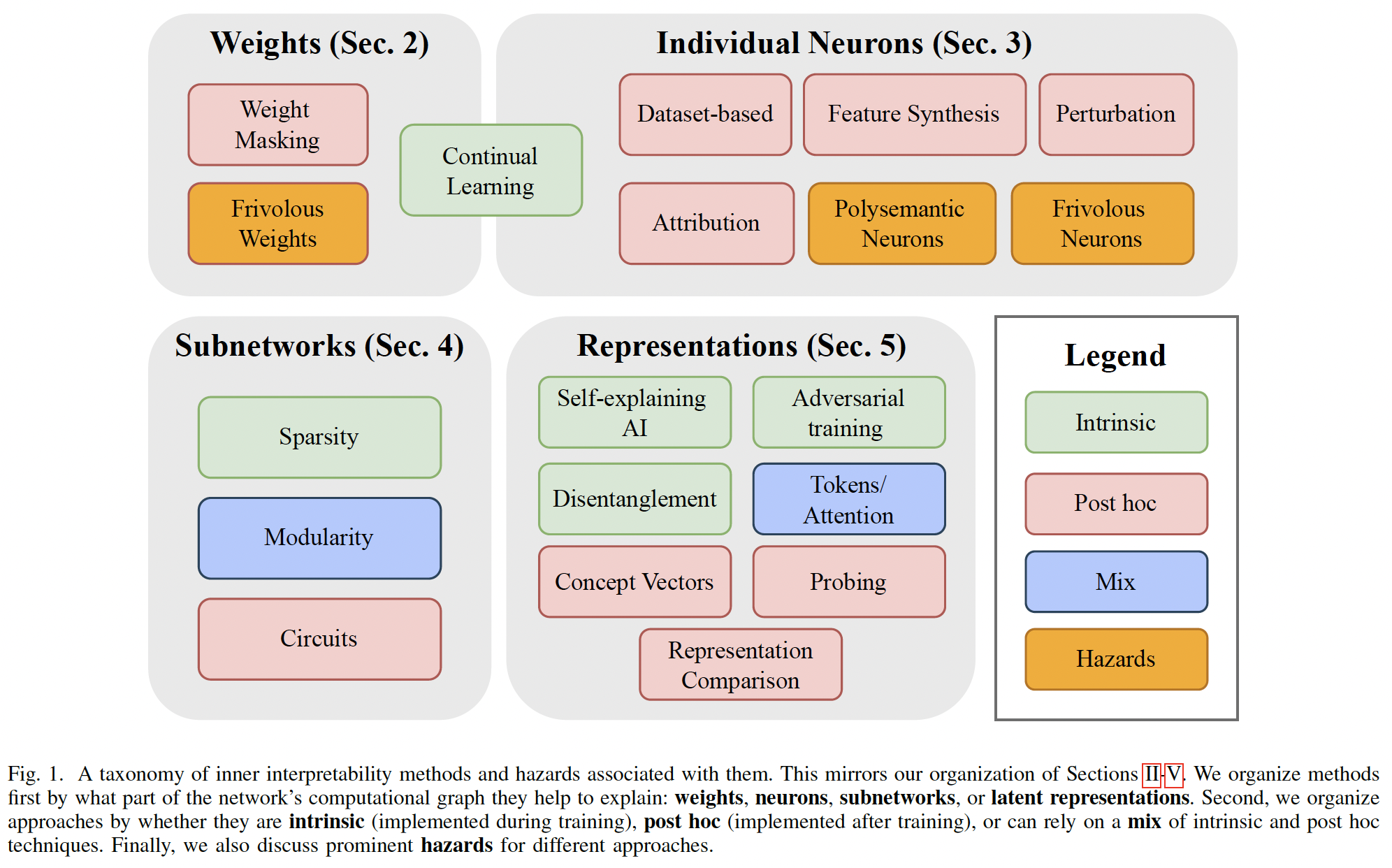 Abstract—The last decade of machine learning has seen drastic increases in scale and ca…
Large language models like ChatGPT don’t just learn facts—they pick up on patterns of behavior. That means they can start to act like different “personas,” or types of people, based on the content the…
Mechanistic interpretability seeks to understand neural networks by breaking them into components that are more easily understood than the whole. By understanding the function of each component, and h…
Disentangling model activations into meaningful features is a central problem in interpretability. However, the absence of ground-truth for these features in realistic scenarios makes validating recen…
As AI systems increasingly make critical decisions, deceptive AI poses a significant challenge to trust and safety. We present Self-Other Overlap (SOO) fine-tuning, a promising approach in AI Safety t…
Finding human-understandable circuits in language models is a central goal of the field of mechanistic interpretability. We train models to have more understandable circuits by constraining most of th…
Foundation models are premised on the idea that sequence prediction can uncover deeper domain understanding, much like how Kepler’s predictions of planetary motion later led to the discovery of Newton…