Current Large Language Models (LLMs) are not only limited to some maximum context length, but also are not able to robustly consume long inputs. To address these limitations, we propose ReadAgent, an …
As autonomous AI agents increasingly navigate the web, they face a novel challenge: the information environment itself. This gives rise to a critical vulnerability we refer to as "AI Agent Traps" — ad…
AI agents are increasingly used in long, multi-turn workflows in both research and enterprise settings. As interactions grow, agent behavior often degrades due to loss of constraint focus, error accum…
Despite the potential of language model-based agents to solve real-world tasks such as web navigation, current methods still struggle with long-horizon tasks with complex action trajectories. In contr…
In this paper, we introduce a novel learning paradigm for adaptive Large Language Model (LLM) agents that eliminates the need for fine-tuning the underlying LLMs. Existing approaches are often either …
Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation—modifying inputs with instructions, strategies, or evidence, rather than we…
The situated view of cognition holds that intelligent behavior depends not only on internal memory, but on an agent’s active use of environmental resources. Here, we begin formalizing this intuition w…
To break the context limits of large language models (LLMs) that bottleneck reasoning accuracy and efficiency, we propose the Thread Inference Model (TIM1), a family of LLMs trained for recursive and …
Language agents have shown some ability to interact with an external environment, e.g., a virtual world such as ScienceWorld, to perform complex tasks, e.g., growing a plant, without the startup costs…
Narrative comprehension on long stories and novels has been a challenging domain attributed to their intricate plotlines and entangled, often evolving relations among characters and entities. Given th…
Maintaining long-term conversations has always been a long-term pursuit in current open-domain dialogue systems (Liu et al., 2016; Zhang et al., 2018; Kann et al., 2022; Song et al., 2023), commonly k…
While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computat…
In the field of natural language processing, open-domain chatbots have emerged as an important research topic. However, a major limitation of existing open-domain chatbot research is its singular focu…
Large Language Models (LLMs) perform well on reasoning benchmarks but often fail when inputs alter slightly, raising concerns about the extent to which their success relies on memorization. This issue…
https:// CGMI: Configurable General Multi-Agent Interaction Framework [https://arxiv.org/abs/2308.12503](https://arxiv.org/abs/2308.12503) [[Memory]] [[Role Play]] “With the capabilities of large …
Non-parametric neural language models (NLMs) learn predictive distributions of text utilizing an external datastore, which allows them to learn through explicitly memorizing the training datapoints. W…
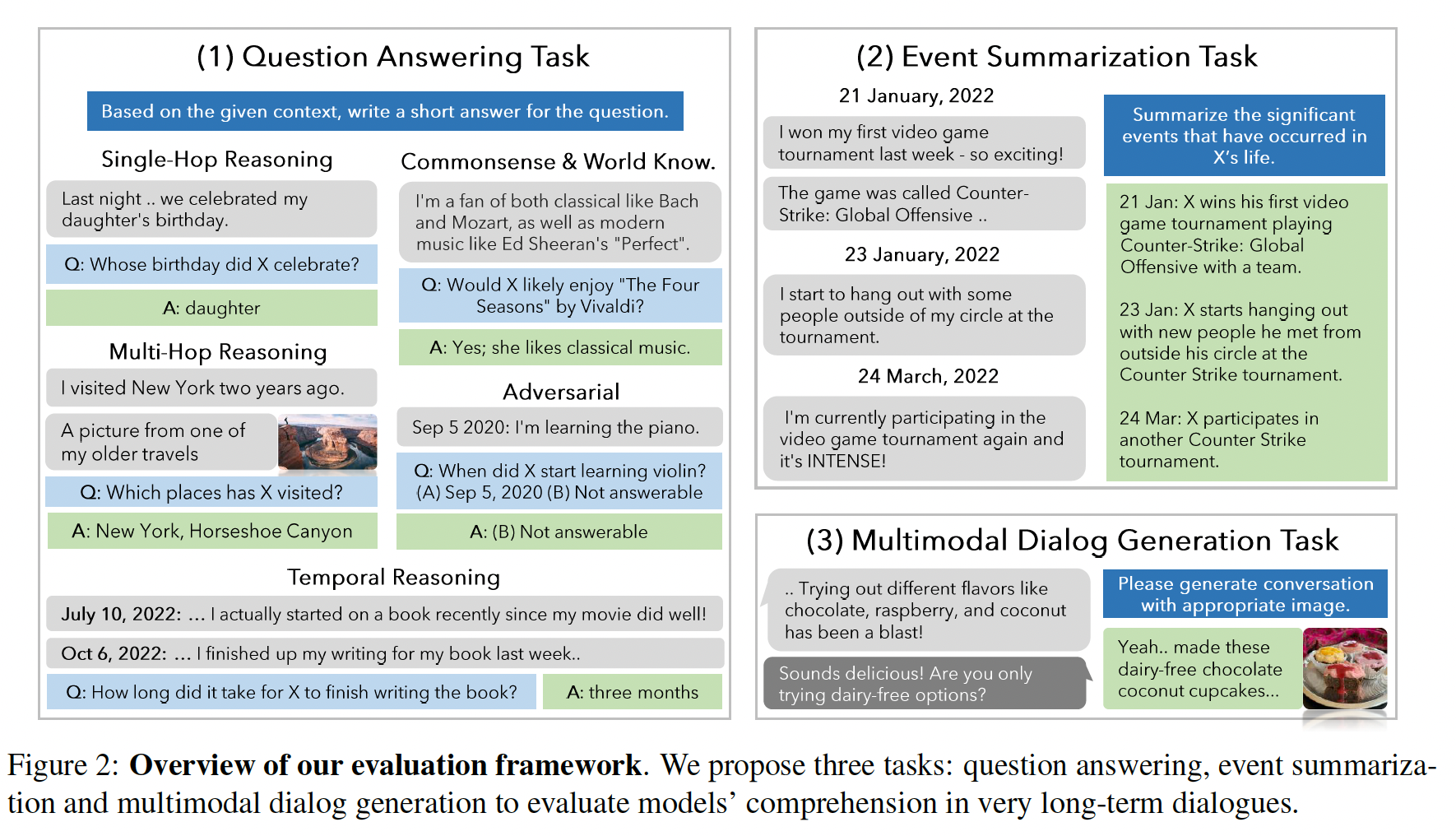 Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning n…
Large language model (LLM) agents are increasingly built less by changing model weights than by reorganizing the runtime around them. Capabilities that earlier systems expected the model to recover in…
RAISE, an enhancement of the ReAct framework, incorporates a dual-component memory system, mirroring human short-term and long-term memory, to maintain context and continuity in conversations. It enta…
This paper studies the next major bottleneck in agentic AI as system scaling, not only model scaling: the design of auditable, persistent, modular, and verifiable architectures around foundation model…
We introduce kNN-LMs, which extend a pre-trained neural language model (LM) by linearly interpolating it with a k-nearest neighbors (kNN) model. The nearest neighbors are computed according to distanc…
“Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, …
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT…
Large Language Models (LLMs) have demonstrated the ability to tackle increasingly complex tasks through advanced reasoning, long-form content generation, and tool use. Solving these tasks often involv…
We propose a new method for estimating how much a model “knows” about a datapoint and use it to measure the capacity of modern language models. We formally separate memorization into two components: u…
![[Pasted image 20251216072354.png]] Designing efficient and effective architectural backbones has been in the core of research efforts to enhance the capability of foundation models. Inspired by the…
Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consol…
The past few decades have witnessed significant advances in the design of machine learning algorithms–from early studies on task-specific shallow models to more general deep Large Language Models (LLM…
As in any conversation in natural language, queries in conversational search may involve omissions, references to previous turns, and ambiguities [32]. Thus, a primary challenge for effective conversa…
Abstract. The increasing demand for web-based digital assistants has given a rapid rise in the interest of the Information Retrieval (IR) community towards the field of conversational question answeri…
Can we localize the weights and mechanisms used by a language model to memorize and recite entire paragraphs of its training data? In this paper, we show that while memorization is spread across multi…
Large language model (LLM) agents rely on reusable skills to solve complex tasks. However, existing skill creation approaches treat skills as isolated and static artifacts, limiting their reusability,…
However, there’s also another approach to categorizing memory types for AI agents from a design pattern perspective. Sarah Wooders from Letta argues that an LLM is a tokens-in-tokens-out function, not…
Large Language Models (LLMs) employ autoregressive decoding that requires sequential computation, with each step reliant on the previous one’s output. This creates a bottleneck as each step necessitat…
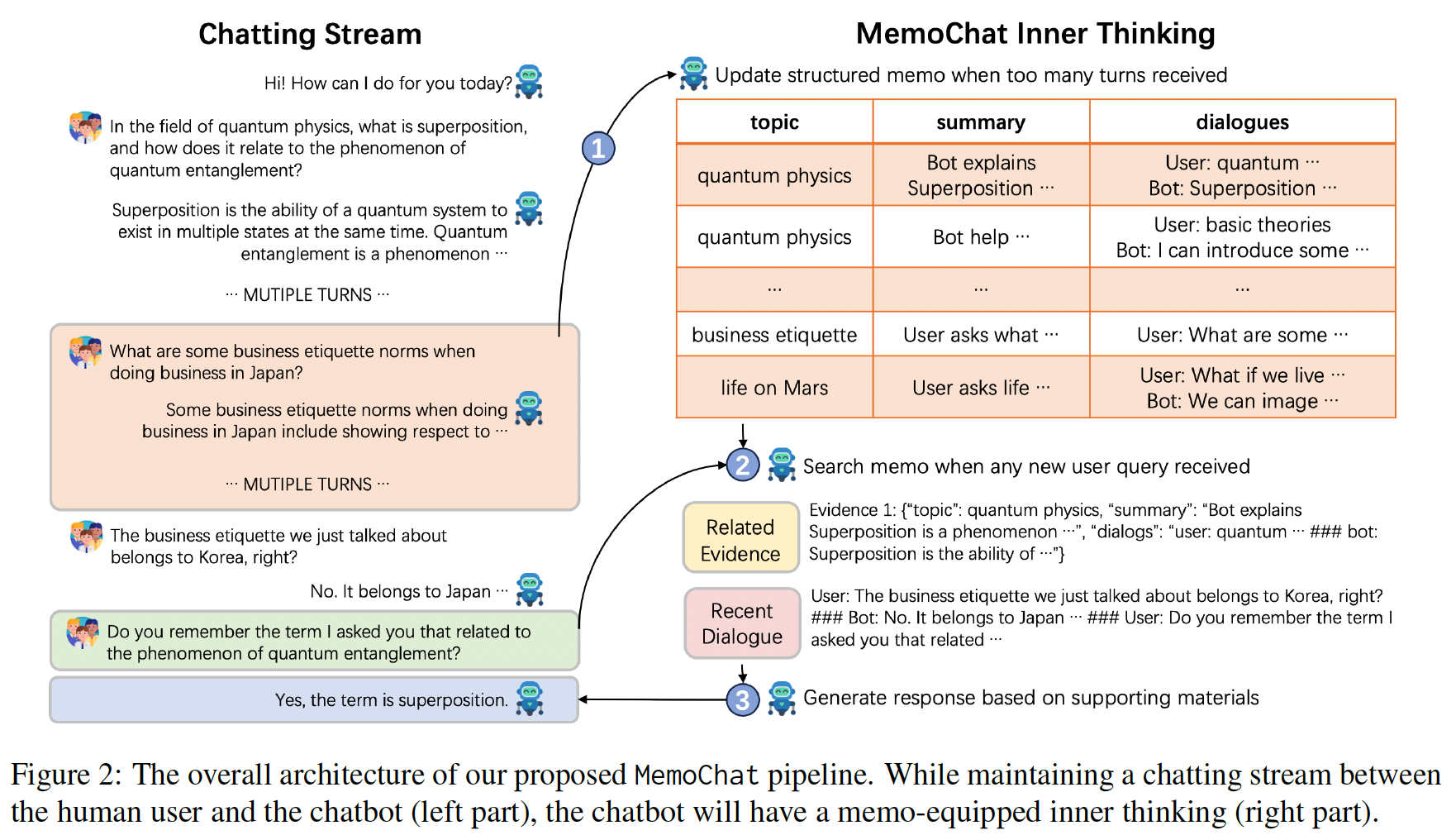 We propose MemoChat, a pipeline for refining instructions that enables large language models (LLMs) to effectively employ self-composed memos…
Large Language Models (LLMs) have shown strong abilities in general language tasks, yet adapting them to specific domains remains a challenge. Current method like Domain Adaptive Pretraining (DAPT) re…
Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. It underpins long-horizon reasoning, continual adaptation, and effective interaction with complex e…
Soft attention is a critical mechanism powering LLMs to locate relevant parts within a given context. However, individual attention weights are determined by the similarity of only a single query and …
In the previous sections, we discussed the concept of nested learning and how existing well-known components of neural networks such as popular optimizers and architectures fall under the NL paradigm.…
Over the last decades, developing more powerful neural architectures and simultaneously designing optimization algorithms to effectively train them have been the core of research efforts to enhance th…
Large language models (LLMs) achieve impressive results on many benchmarks, yet their capacity for planning and stateful reasoning remains unclear. We study these abilities directly, without code exec…
Large language model (LLM) personalization aims to align model outputs with individuals’ unique preferences and opinions. While recent efforts have implemented various personalization methods, a unifi…
The capabilities and limitations of Large Language Models (LLMs) have been sketched out in great detail in recent years, providing an intriguing yet conflicting picture. On the one hand, LLMs demonstr…
To obtain trustworthy evaluation signals, we introduce a generator that creates fully synthetic arithmetic problems of arbitrary length and difficulty, yielding clean datasets we call RandomCalculatio…
With the growing adoption of large language model agents in persistent real-world roles, they naturally encounter continuous streams of tasks. A key limitation, however, is their failure to learn from…
Existing memory-augmented LLM agents often treat memory as a static repository with pre-defined representations and fixed retrieval pipelines, which is brittle in dynamic agentic environments where fe…
Users interact with chatbots for various purposes and motivations – and for different periods of time. However, since chatbots are considered social actors and given that time is an essential componen…
Imagine that in the future a household robot can autonomously carry out household tasks without your explicit instructions; it must have learned the operational rules of your home through daily experi…
Large Language Model (LLM) agents have shown stunning results in complex tasks, yet they often operate in isolation, failing to learn from past experiences. Existing memory-based methods primarily sto…
Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models (LLMs) and Multi-Modal LLMs (MLLMs). As these models transition from…
Abstract—Humans have a selective memory, remembering relevant episodes and forgetting the less relevant information. Possessing awareness of event memorability for a user could help intelligent system…
Memory-augmented Large Language Models (LLMs) have demonstrated remarkable performance in long-term human-machine interactions, which basically relies on iterative recalling and reasoning of history t…
Over more than a decade there has been an extensive research effort of how effectively utilize recurrent models and attentions. While recurrent models aim to compress the data into a fixed-size memory…
There has recently been growing interest in conversational agents with long-term memory which has led to the rapid development of language models that use retrieval-augmented generation (RAG). Until r…
Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency — which is crucial for r…
Learning from past experience benefits from two complementary forms of memory: episodic traces—raw trajectories of what happened—and consolidated abstractions distilled across many episodes into reusa…