Prompt tuning has emerged as a promising parameter-efficient fine-tuning (PEFT) approach that offers several advantages: (1) parameter efficiency through updating only a small group of continuous vect…
This report provides a comprehensive taxonomy of LLM hallucinations, beginning with a formal definition and a theoretical framework that posits its inherent inevitability in computable LLMs, irrespect…
Large language models (LLMs) are increasingly being used as decision aids. However, users have diverse values and preferences that can affect their decision-making, which requires novel methods for LL…
Since the success of GPT, large language models (LLMs) have been revolutionizing machine learning and have initiated the so-called LLM prompting paradigm. In the era of LLMs, people train a single gen…
“Prompt-tuning has become an increasingly popular parameter-efficient method for adapting large pretrained language models to downstream tasks. However, both discrete prompting and continuous promptin…
The remarkable success of pretrained language models has motivated the study of what kinds of knowledge these models learn during pretraining. Reformulating tasks as fillin-the-blanks problems (e.g., …
“The recent success in large language models (LLMs) has shown that properly prompted LLMs demonstrate emergent capabilities on complex understanding and question-answering tasks (Wei et al., 2022a). E…
Large Language Models (LLMs) have shown impressive performance as general purpose agents, but their abilities remain highly dependent on prompts which are hand written with onerous trial-and-error eff…
Large Language Models (LLMs) have been widely deployed in reasoning, planning, and decision-making tasks, making their trustworthiness a critical concern. The potential for intentional deception, wher…
we propose a prompt ensembling method for large language models, which uses a small dataset to construct a set of few shot prompts that together comprise a “boosted prompt ensemble”. The few shot exam…
Large language models (LLMs) exhibit dynamic capabilities and appear to comprehend complex and ambiguous natural language prompts. However, calibrating LLM interactions is challenging for interface de…
Large Language Models (LLMs) have recently achieved impressive results in complex reasoning tasks through Chain of Thought (CoT) prompting. However, most existing CoT methods rely on using the same pr…
Abstract—This thesis investigates whether large language models (LLMs) can be guided to simulate a consistent personality through prompt engineering. The study explores this concept within the context…
We propose CoT-Self-Instruct, a synthetic data generation method that instructs LLMs to first reason and plan via Chain-of-Thought (CoT) based on the given seed tasks, and then to generate a new synth…
Large language models (LLMs) have significantly advanced the field of artificial intelligence. Yet, evaluating them comprehensively remains challenging. We argue that this is partly due to the predomi…
We study the task of prompting large-scale language models to perform multistep reasoning. Existing work shows that when prompted with a chain of thoughts (CoT), sequences of short sentences describin…
Conversational Prompt Engineering (CPE), a user-friendly tool that helps users create personalized prompts for their specific tasks. CPE uses a chat model to briefly interact with users, helping them …
Few-shot prompting is a surprisingly powerful way to use Large Language Models (LLMs) to solve various tasks. However, this approach struggles as the task complexity increases or when the individual r…
We view large language models (LLMs) as stochastic language layers in a network, where the learnable parameters are the natural language prompts at each layer. We stack two such layers, feeding the ou…
Task-oriented conversational systems often use dialogue state tracking to represent the user’s intentions, which involves filling in values of pre-defined slots. Many approaches have been proposed, of…
Recently, a boom of papers has shown extraordinary progress in zero-shot and few-shot learning with various prompt-based models. It is commonly argued that prompts help models to learn faster in the s…
the efficacy of employing fixed soft prompts with a predetermined position for concatenation with inputs for all instances, irrespective of their inherent disparities, remains uncertain. Variables suc…
“Large language models (LLMs) have achieved significant performance in many fields, such as reasoning, language understanding, and math problem-solving, and are regarded as an important step to artifi…
In the era of Large Language Models, we believe it is the right time to develop AI assistance for computational psychotherapy. We study the task of cognitive distortion detection and propose the Diagn…
One emergent ability of large language models (LLMs) is that query-specific examples can be included in the prompt at inference time. In this work, we use active learning for adaptive prompt design an…
Transformer language models have demonstrated impressive generalization capabilities in natural language domains, yet we lack a fine-grained understanding of how such generalization arises. In this pa…
Large Language Models (LLMs), in the recent years, have become more sophisticated and capable for them to be applicable in many situations and tasks. These tasks are not limited to information extract…
Selecting the “right” amount of information to include in a summary is a difficult task. A good summary should be detailed and entity-centric without being overly dense and hard to follow. To better u…
In this paper, we propose and empirically investigate a prompt engineering-based approach to generate proto-personas with the support of Generative AI (GenAI). Our goal is to evaluate the approach in …
“Since directly optimizing LLMs for specific tasks is either inefficient and infeasible for most users and developers, researchers resort to optimizing prompts instead. Prompt engineering approaches, …
Production-grade LLM systems require robust adherence to dozens or even hundreds of instructions simultaneously. However, the instruction-following capabilities of LLMs at high instruction densities h…
In-context learning (ICL, also known as fewshot prompting) has been the standard method of adapting LLMs to downstream tasks, by learning from a few input-output examples. Nonetheless, all ICL-based a…
Prompt optimization methods have demonstrated significant effectiveness in aligning black-box large language models (LLMs). In parallel, inference scaling strategies such as BEST-OF-N Sampling and MAJ…
the efficacy of a singular, task-level prompt uniformly applied across the whole of instances is inherently limited since one prompt cannot be a good partner for all, a more appropriate approach shoul…
**The Instruction Paradigm** Efrat and Levy [2020] propose to learn new tasks from natural language instructions. Mishra et al. [2022] and Wang et al. [2022b] collect crowdsourcing instructions used t…
Language models can behave in unexpected and unsafe ways, and so it is valuable to monitor their outputs. Internal activations of language models encode additional information that could be useful for…
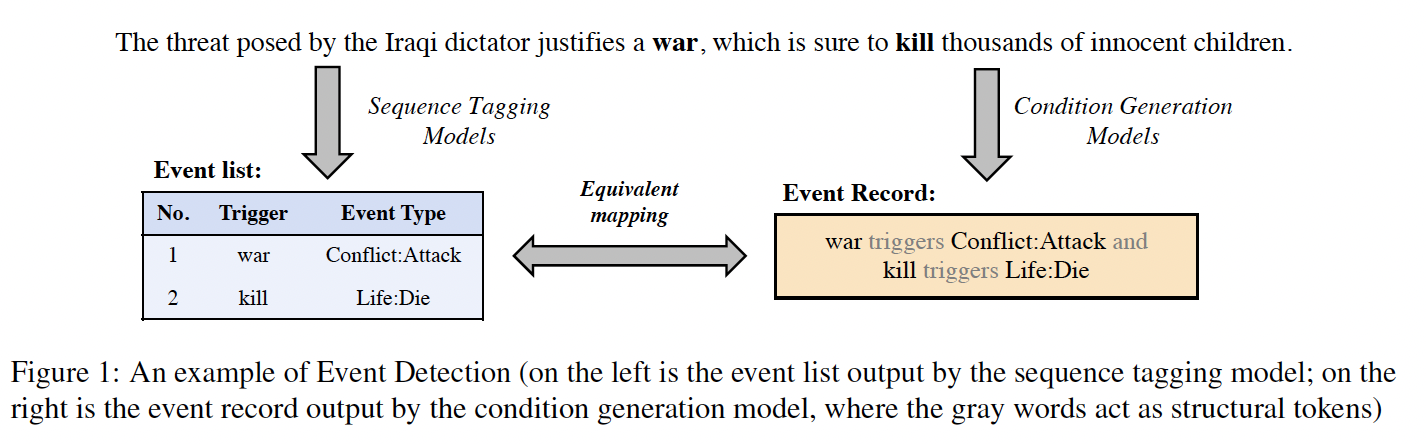 Event detection aims to detect events from the text by identifying and classifying event triggers (t…
We introduce “Method Actors” as a mental model for guiding LLM prompt engineering and prompt architecture. Under this mental model, LLMs should be thought of as actors; prompts as scripts and cues; an…
“Prompt Engineering Prompting offers a natural and intuitive interface for humans to interact with and use generalist models such as LLMs. Due to its flexibility, prompting has been widely used as a g…
 In-context learning is a recent paradigm in natural language understanding, where a large pre-…
Large language models (LLMs) are trained for downstream tasks by updating their parameters (e.g., via RL). However, updating parameters forces them to absorb task-specific information, which can resul…
This paper discusses our approaches for taskoriented conversational modelling using subjective knowledge, with a particular emphasis on response generation. Our methodology was shaped by an extensive …
“While previous research primarily focuses on refining the logical progression of responses, the concept of metacognition— often defined as “thinking about thinking”—offers a unique perspective. Origi…
{okd5069@psu.edu, akhilkumar@psu.edu} Abstract The wording of natural language prompts has been shown to influence the performance of large language models (LLMs), yet the role of politeness and tone …
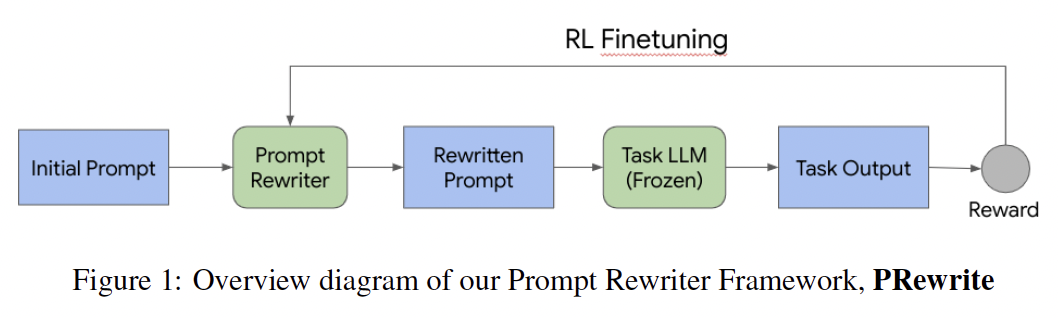 Prompt engineering is critical for the development of LLM-based applications. However, it is usually…
As large language models (LLMs) have shown effectiveness with different prompting methods, such as Chain of Thought, Program of Thought, we find that these methods have formed a great complementarity …
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub “prompt-based learning”. Unlike traditional supervised learning, which trains a model to …
Fine-tuning is the de facto way of leveraging large pretrained language models for downstream tasks. However, fine-tuning modifies all the language model parameters and therefore necessitates storing …
Large language models (LLMs) have demonstrated impressive capabilities across various tasks, but their performance is highly sensitive to the prompts utilized. This variability poses challenges for ac…
The performance of Large Language Models (LLMs) in reasoning tasks depends heavily on prompt design, with Chain-of-Thought (CoT) and self-consistency being critical methods that enhance this ability. …
The car wash problem asks a simple question: “I want to wash my car. The car wash is 100 meters away. Should I walk or drive?” Every major LLM tested—Claude, GPT-4, Gemini— recommended walking. The co…
“Prior to GPT-3, the standard approach to the evaluation and use of such models has involved fine- tuning on a portion of a task dataset [12]. GPT-3 achieved state-of-the-art performance on a wide var…
Popular prompt strategies like Chain-of-Thought Prompting can dramatically improve the reasoning abilities of Large Language Models (LLMs) in various domains. However, such hand-crafted prompt-strateg…
It has become routine to report research results where Large Language Models (LLMs) outperform average humans in a wide range of language-related tasks, and creative text writing is no exception. It s…
Retrieval-augmented generation (RAG) has shown great promise for knowledge-intensive tasks and recently advanced with agentic RAG, where language agents engage in multi-round interactions with externa…
“Of course, recent years have also witnessed a dramatic rise in the capabilities of general-purpose (non-finetuned) large pretrained language models. Of particular note are their strong zero-shot capa…
Human reasoning involves different strategies, each suited to specific problems. Prior work shows that large language model (LLMs) tend to favor a single reasoning strategy, potentially limiting their…
Large language models (LLMs) can perform recommendation tasks by taking prompts written in natural language as input. Compared to traditional methods such as collaborative filtering, LLM-based recomme…
Here we advocate two basic metaphors for LLM-based dialogue agents. First, taking a simple and intuitive view, we can see a dialogue agent as role-playing a single character. Second, taking a more nua…
However, the closed-source nature of state-of-the-art LLMs and their general-purpose training limit role-playing optimization. In this paper, we introduce RoleLLM, a framework to benchmark, elicit, an…
*Table 2. All 39 reasoning modules consisting of high-level cognitive heuristics for problem-solving. We adopt them from Fernando et al.* (_2023_). Reasoning Modules 1 How could I devise an experim…
We investigate how to elicit compositional generalization capabilities in large language models (LLMs). Compositional generalization empowers LLMs to solve complex problems by combining foundational s…
This research explores strategies for steering the output of large language models (LLMs) towards specific styles, such as sentiment, emotion, or writing style, by adding style vectors to the activati…
Conceptual design can be modeled as a proposition making process, where designers make logical propositions to communicate and construct intangible concepts. Not only can LLMs interpret designers’ pro…
Test-time compute has led to remarkable success in the large language model (LLM) community, particularly for complex tasks, where longer chains of thought (CoTs) are generated to enhance reasoning ca…
I have the v2, published Dec 30 We note that the transition dynamics between states depend primarily on the verb used in the action (e.g., take, put, cook, ...). Predicting action-driven transitions…
Abstract. While large language models demonstrate impressive performance on static benchmarks, the true potential of large language models as self-learning and reasoning agents in dynamic environments…
In this study, we propose a class of compact yet effective prompts (~30 tokens in length) that synthetically fuse semantically distant concepts in ways that resist scientific integration—such as combi…
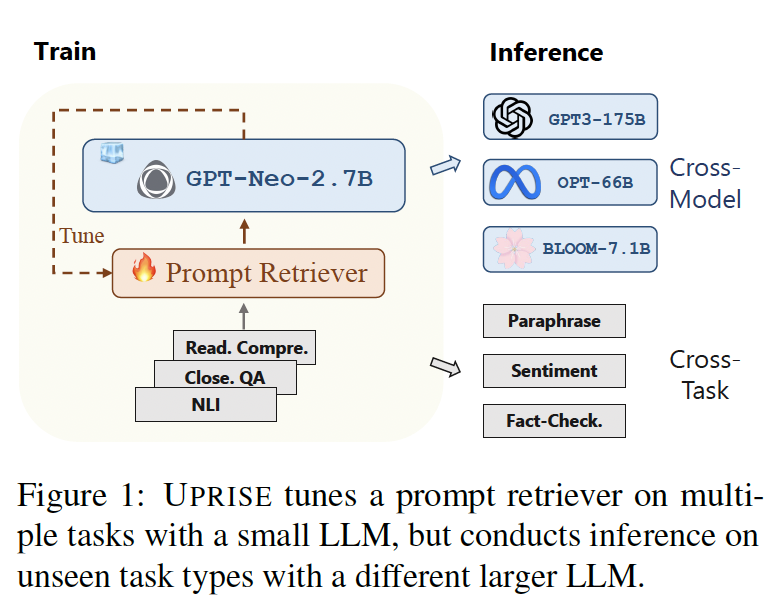 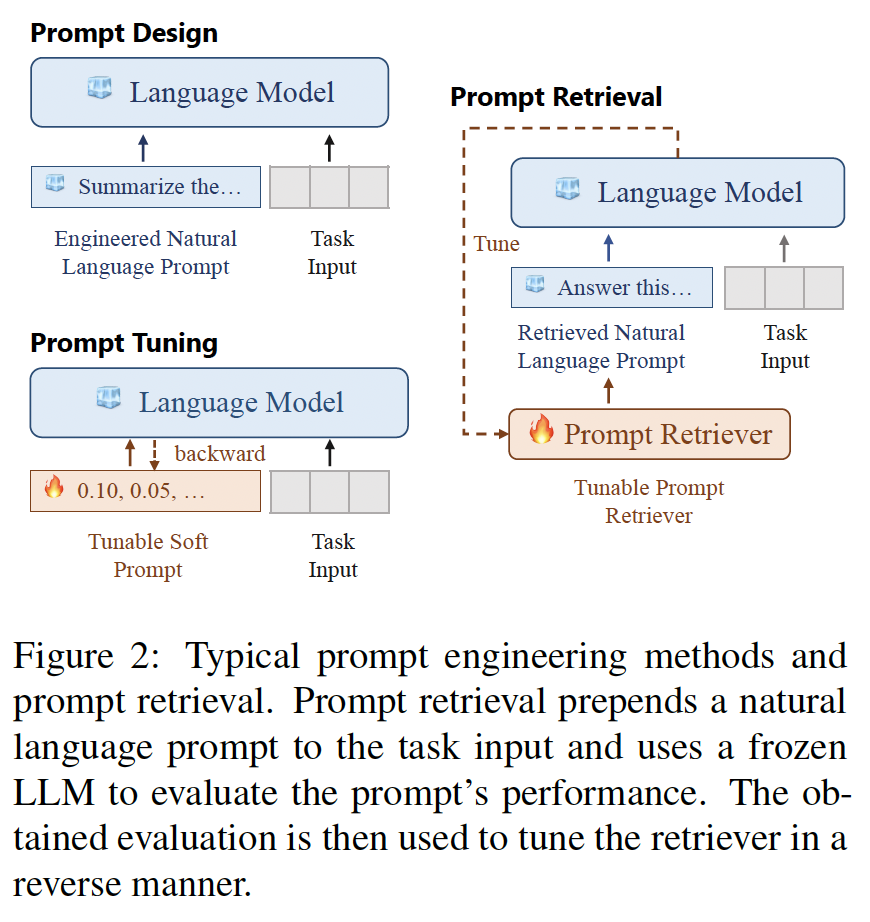 Large Language Models (LLMs) are popular for their impressive abilities, but …
Despite the importance of understanding natural language prompts, there remains limited consensus on how to quantify them. Current approaches rely predominantly on outcome-centric measurements, such a…
Large Language Models (LLMs) have demonstrated impressive performance in code generation tasks under idealized conditions, where task descriptions are clear and precise. However, in practice task desc…