Abstract: Large Language Models (LLMs) have demonstrated significant capabilities in understanding and generating human language, contributing to more natural interactions with complex systems. Howeve…
The rapid advancement of chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be…
Abstract—This thesis investigates whether large language models (LLMs) can be guided to simulate a consistent personality through prompt engineering. The study explores this concept within the context…
Can Large Language Models (LLMs) simulate humans in making important decisions? Recent research has unveiled the potential of using LLMs to develop role-playing language agents (RPLAs), mimicking main…
Large Language Models (LLMs) are increasingly used to simulate human users in interactive settings such as therapy, education, and social role-play. While these simulations enable scalable training an…
Large language models (LLMs) provide a compelling foundation for building generally-capable AI agents. These agents may soon be deployed at scale in the real world, representing the interests of indiv…
https:// CGMI: Configurable General Multi-Agent Interaction Framework [https://arxiv.org/abs/2308.12503](https://arxiv.org/abs/2308.12503) [[Memory]] [[Role Play]] “With the capabilities of large …
As large language models (LLMs) are increasingly studied as role-playing agents to generate synthetic data for human behavioral research, ensuring that their outputs remain coherent with their assigne…
Recent advancements in Large Language Models (LLMs) have shown promising performance on ToM benchmarks, raising the question: Do these benchmarks necessitate explicit human-like reasoning processes, o…
We present Heart-to-Heart Talk (H2HTalk), a benchmark assessing companions across personality development and empathetic interaction, balancing emotional intelligence with linguistic fluency. H2HTalk …
LLMs have shown strong performance on human-centric reasoning tasks. While previous evaluations have explored whether LLMs can infer intentions or detect deception, they often overlook the individuali…
Neural language models (LMs) represent facts about the world described by text. Sometimes these facts derive from training data (in most LMs, a representation of the word banana encodes the fact that …
What does it truly mean for a language model to “reason” strategically, and can scaling up alone guarantee intelligent, context-aware decisions? Strategic decision-making requires adaptive reasoning, …
We introduce “Method Actors” as a mental model for guiding LLM prompt engineering and prompt architecture. Under this mental model, LLMs should be thought of as actors; prompts as scripts and cues; an…
Human social interactions depend on the ability to infer others’ unspoken intentions, emotions, and beliefs—a cognitive skill grounded in the psychological concept of Theory of Mind (ToM). While large…
Achieving cooperation among self-interested agents remains a fundamental challenge in multi-agent reinforcement learning. Recent work showed that mutual cooperation can be induced between “learningawa…
However, systematic exploration of their dual capabilities to autonomously persuade and resist persuasion, particularly in contexts involving psychological rhetoric, remains unexplored. In this paper,…
Our approach involves evaluating the intrinsic personality traits of Open LLM agents and determining the extent to which these agents can mimic human personalities when conditioned by specific persona…
The ability to understand and predict the mental states of oneself and others, known as the Theory of Mind (ToM), is crucial for effective social scenarios. Although recent studies have evaluated ToM …
We introduce MBTI-in-Thoughts, a framework for enhancing the effectiveness of Large Language Model (LLM) agents through psychologically grounded personality conditioning. Drawing on the Myers–Briggs T…
Here we advocate two basic metaphors for LLM-based dialogue agents. First, taking a simple and intuitive view, we can see a dialogue agent as role-playing a single character. Second, taking a more nua…
Murray Shanahan “What sorts of roles might the agent begin to take on? This is determined in part, of course, by the tone and subject matter of the ongoing conversation. But it is also determined, i…
However, the closed-source nature of state-of-the-art LLMs and their general-purpose training limit role-playing optimization. In this paper, we introduce RoleLLM, a framework to benchmark, elicit, an…
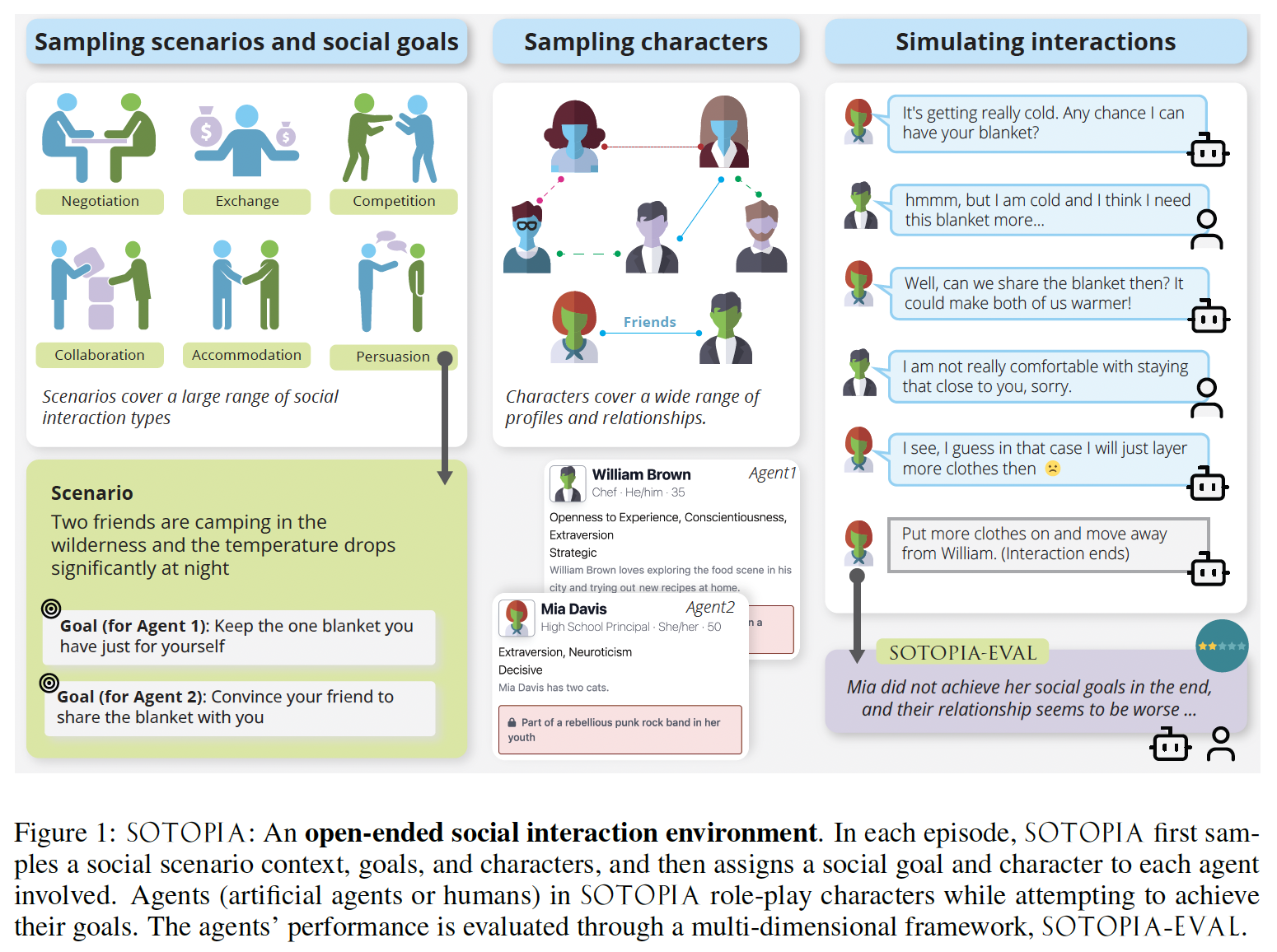 **** In our environment, agents role-play and interact under a wide variety of scenarios; they coordinate, collaborate, exchange, and comp…
Self-improving systems require environmental interaction for continuous adaptation. We introduce SPICE (Self-Play In Corpus Environments), a reinforcement learning framework where a single model acts …
As Large Language Models (LLMs) gain agentic abilities, they will have to navigate complex multiagent scenarios, interacting with human users and other agents in cooperative and competitive settings. …
Large language models (LLMs) excel at complex reasoning tasks such as mathematics and coding, yet they frequently struggle with simple interactive tasks that young children perform effortlessly. This …
The advancement of Large Language Models (LLMs) has spurred significant interest in Role-Playing Agents (RPAs) for applications such as emotional companionship and virtual interaction. However, recent…
Large Language Models (LLMs) are increasingly tasked with creative generation, including the simulation of fictional characters. However, their ability to portray non-prosocial, antagonistic personas …
As AI systems increasingly make critical decisions, deceptive AI poses a significant challenge to trust and safety. We present Self-Other Overlap (SOO) fine-tuning, a promising approach in AI Safety t…
Communicating in natural language is a powerful tool in multiagent settings, as it enables independent agents to share information in partially observable settings and allows zero-shot coordination wi…
The concept of persona, originally adopted in dialogue literature, has re-surged as a promising framework for tailoring large language models (LLMs) to specific context (e.g., personalized search, LLM…
David Chalmers [[Linguistics, NLP, NLU]] [[Role Play]] [[Philosophy Subjectivity]] Quasi-interpretivism does not say anything about whether LLMs have beliefs and desires. But it does make it plausib…