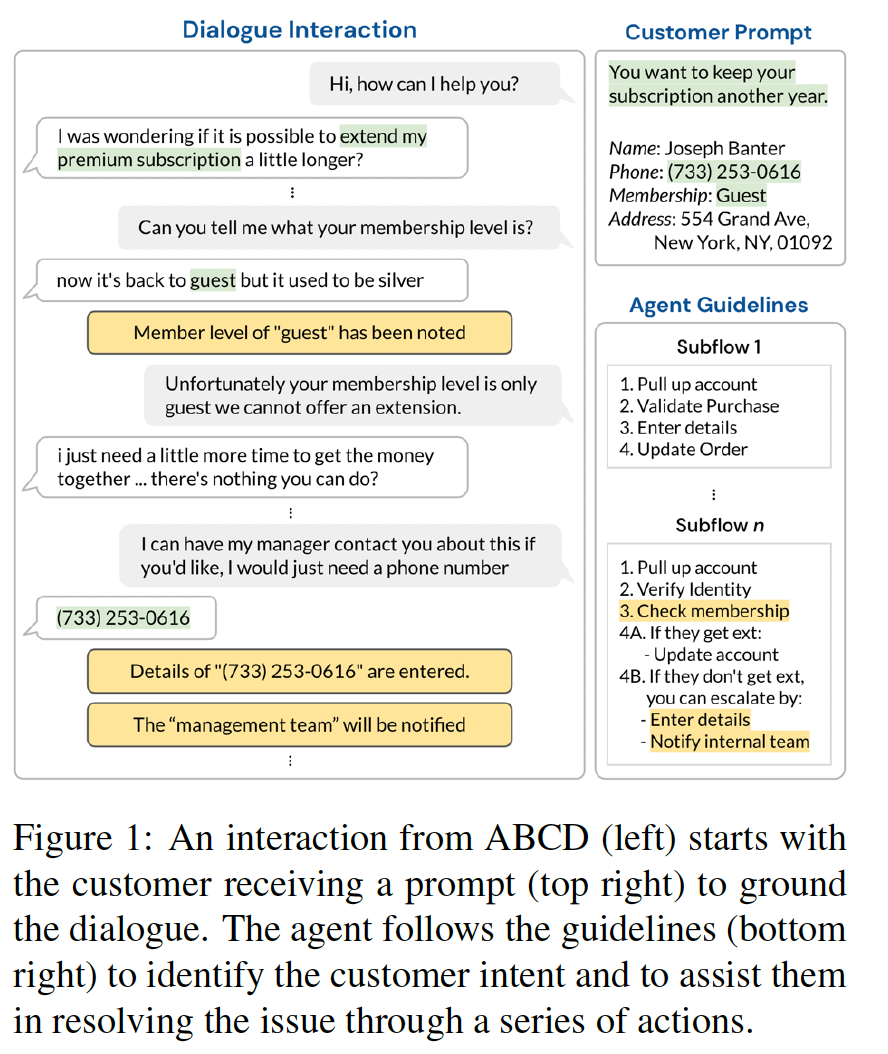
 Existing goal-oriented dialogue datasets focus mainly on identifying slots and values. However, customer sup…
In this paper, we introduce a novel learning paradigm for adaptive Large Language Model (LLM) agents that eliminates the need for fine-tuning the underlying LLMs. Existing approaches are often either …
Furthermore, planning ability is a crucial component of an LLM-based agent, involving interaction with the environment and executing actions to complete a planning task, which generally entails achiev…
The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and…
We present Attentive Reasoning Queries (ARQs), a novel structured reasoning approach that significantly improves instruction-following in Large Language Models through domain-specialized reasoning blu…
Building autonomous machines that can explore open-ended environments, discover possible interactions and build repertoires of skills is a general objective of artificial intelligence. Developmental a…
Large Language Models (LLMs) are frequently used for multi-faceted language generation and evaluation tasks that involve satisfying intricate user constraints or taking into account multiple aspects a…
Large language models (LLMs) exhibit dynamic capabilities and appear to comprehend complex and ambiguous natural language prompts. However, calibrating LLM interactions is challenging for interface de…
There have been widespread claims about Large Language Models (LLMs) being able to successfully verify or self-critique their candidate solutions in reasoning problems in an iterative mode. Intrigued …
Their seeming versatility has however led many researchers to wonder whether they can also do well on planning and reasoning tasks typically associated with System 2 competency. Nothing in the traini…
Cognitive assistants (CA) are chatbots that provide context-aware support to human workers in knowledge-intensive tasks. Traditionally, cognitive assistants respond in specific ways to predefined user…
 We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It…
We consider a new perspective on dialog state tracking (DST), the task of estimating a user’s goal through the course of a dialog. By formulating DST as a semantic parsing task over hierarchical repre…
Real-time human-artificial intelligence (AI) collaboration is crucial yet challenging, especially when AI agents must adapt to diverse and unseen human behaviors in dynamic scenarios. Existing large l…
“All these situations share an underlying structured decision problem in the face of uncertainty, where communicating and collaborating with others is often critical to arrive at the best solution. D…
Conversational AI assistants promise to help users achieve a task through natural language. Interpreting simple instructions like please turn on the lights is relatively straightforward, but to handle…
While Large Language Models (LLMs) can solve many NLP tasks in zero-shot settings, applications involving embodied agents remain problematic. In particular, complex plans that require multi-step reaso…
To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools…
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computati…
Abstract—Autonomous agent systems powered by Large Language Models (LLMs) have demonstrated promising capabilities in automating complex tasks. However, current evaluations largely rely on success rat…
The integration of Natural Language Processing (NLP) and AI into legal tasks is a natural progression, given the linguistic nature of law. This combination allows for more efficient and accurate analy…
Multi-agent systems (MAS) powered by large language models (LLMs) increasingly adopt planner–executor architectures, where planners convert prompts into subtasks, roles, dependencies, and routing path…
We present Federation of Agents (FoA), a distributed orchestration framework that transforms static multi-agent coordination into dynamic, capability-driven collaboration. FoA introduces Versioned Cap…
RAISE, an enhancement of the ReAct framework, incorporates a dual-component memory system, mirroring human short-term and long-term memory, to maintain context and continuity in conversations. It enta…
However, the sequential decision making setting poses additional challenges having a lower tolerance for errors since the environment’s stochasticity or the agent’s actions can lead to unseen, and som…
Large language models (LLMs) are increasingly seen as assistants, copilots, and consultants, capable of supporting a wide range of tasks through natural conversation. However, most systems remain cons…
Planning is a fundamental property of human intelligence. Reasoning about asynchronous plans is challenging since it requires sequential and parallel planning to optimize time costs. Can large languag…
Recently, large reasoning models have demonstrated strong mathematical and coding abilities, and deep search leverages their reasoning capabilities in challenging information retrieval tasks. Existing…
 Task-oriented dialogue is difficult in part because it involves understanding user inten…
Instruction tuning has unlocked powerful capabilities in large language models (LLMs), using combined datasets to develop general-purpose chatbots. However, real-world applications often require a spe…
Abstract: Large language models (LLMs) have demonstrated remarkable zeroshot generalization abilities: state-of-the-art chatbots can provide plausible answers to many common questions that arise in da…
Developing domain models is one of the few remaining places that require manual human labor in AI planning. Thus, in order to make planning more accessible, it is desirable to automate the process of …
Abstract. Business Process Management (BPM) aims to improve organizational activities and their outcomes by managing the underlying processes. To achieve this, it is often necessary to consider inform…
We propose a context-dependent model to map utterances within an interaction to executable formal queries. To incorporate interaction history, the model maintains an interaction-level encoder that upd…
LLM-as-a-Judge models generate chain-of-thought (CoT) sequences intended to capture the step-by-step reasoning process that underlies the final evaluation of a response. However, due to the lack of hu…
There is a growing interest in applying pre-trained large language models (LLMs) to planning problems. However, methods that use LLMs directly as planners are currently impractical due to several fact…
Tool calling has emerged as a critical capability for AI agents to interact with the real world and solve complex tasks. While the Model Context Protocol (MCP) provides a powerful standardized framewo…
Time series forecasting is not just numerical extrapolation, but often requires reasoning with unstructured contextual data such as news or events. While specialized Time Series Foundation Models (TSF…
Large language models (LLMs) achieve impressive results on many benchmarks, yet their capacity for planning and stateful reasoning remains unclear. We study these abilities directly, without code exec…
we aim to further study the insight of the planning capability of LLMs by investigating the roles of LLMs in off-the-shelf planning frameworks. To do this, we investigate the effectiveness of embeddin…
In this paper, we argue that foundation models such as LLMs can be used for creative reasoning tasks in the engineering design process, complementing and integrating existing computational methods suc…
As large language models (LLMs) have shown effectiveness with different prompting methods, such as Chain of Thought, Program of Thought, we find that these methods have formed a great complementarity …
In this paper, we conduct a study to utilize LLMs as a solution for decision making that requires complex data analysis. We define Decision QA as the task of answering the best decision, dbest, for a …
In proactive dialogue, the challenge lies not just in generating responses but in steering conversations toward predetermined goals, a task where Large Language Models (LLMs) typically struggle due to…
OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs–making it a new kind of model: a Large Reaso…
Proactive dialogues serve as a practical yet challenging dialogue problem in the era of large language models (LLMs), where the dialogue policy planning is the key to improving the proactivity of LLMs…
We present PolyResponse, a conversational search engine that supports task-oriented dialogue. It is a retrieval-based approach that bypasses the complex multi-component design of traditional task-orie…
Large Language Models (LLMs), essentially n-gram models on steroids which have been pre-trained on web-scale language corpora (or, effectively, our collective consciousness), have caught the imaginati…
We hypothesize that cross-domain generalization arises from shared abstract reasoning prototypes — fundamental reasoning patterns that capture the essence of problems across domains. These prototypes …
“While large language models (LLMs) have demonstrated impressive performance across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-though…
Real-world applications of AI Planning often require a highly expressive modeling language to accurately capture important intricacies of target systems. Hybrid systems are ubiquitous in the real-worl…
Large Language Models (LLMs) show potential as sequential decision-making agents, but their application is often limited due to a reliance on large, computationally expensive models. This creates a ne…
We present a new method, SOLOIST,1 that uses transfer learning and machine teaching to build task bots at scale. We parameterize classical modular task-oriented dialog systems using a Transformer-base…
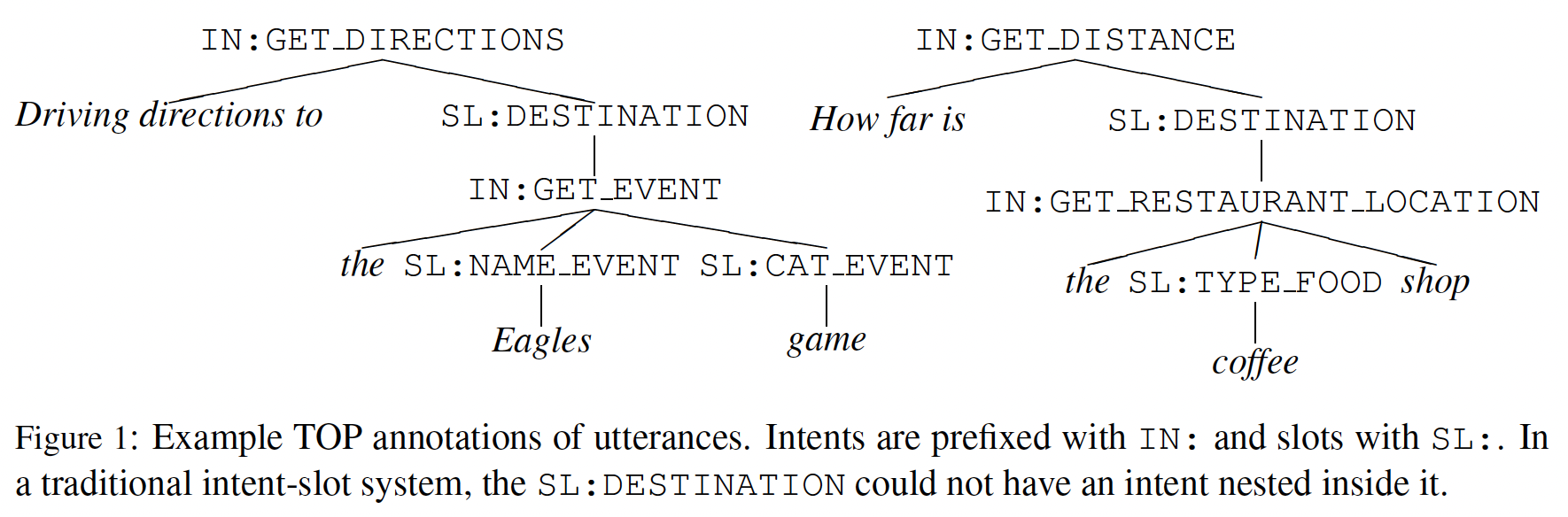 Task oriented dialog systems typically first parse user utterances to semantic frames comprised of intents and s…
The emergence of Large Language Models (LLMs) like ChatGPT has inspired the development of LLM-based agents capable of addressing complex, real-world tasks. However, these agents often struggle during…
we find that on datasets released before the LLM training data creation date, LLMs perform surprisingly better than on datasets released after. This strongly indicates that, for many LLMs, there exist…
We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs i…
We describe a system for building task oriented dialogue systems combining the in context learning abilities of large language models (LLMs) with the deterministic execution of business logic. LLMs ar…
“Structured Complex Task Decomposition (SCTD) is the problem of breaking down a complex real-world task (such as planning a wedding) into a directed acyclic graph over individual steps that contribute…
The emergence of agentic reinforcement learning (Agentic RL) marks a paradigm shift from conventional reinforcement learning applied to large language models (LLM RL), reframing LLMs from passive sequ…
To measure the progress of these LLM agents’ performance on performing real-world professional tasks, in this paper we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that …
Large language models (LLMs) have exhibited remarkable reasoning and planning capabilities. Most prior work in this area has used LLMs to reason through steps from an initial to a goal state or criter…
Supervised fine-tuning (SFT) is a common method to enhance the tool calling capabilities of Large Language Models (LLMs), with the training data often being synthesized. The current data synthesis pro…
Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency — which is crucial for r…
We propose a hybrid approach to machine Theory of Mind (ToM) that uses large language models (LLMs) as a mechanism for generating hypotheses and likelihood functions with a Bayesian inverse planning m…
Efficient exploration is essential for intelligent systems interacting with their environment, but existing language models often fall short in scenarios that require strategic information gathering. …
Recent advances in reinforcement learning (RL) have significantly enhanced the agentic capabilities of large language models (LLMs). In long-term and multi-turn agent tasks, existing approaches driven…
Autonomous agents powered by language models (LMs) have demonstrated promise in their ability to perform decision-making tasks such as web automation. However, a key limitation remains: LMs, primarily…
Abstract— Classical planning formulations like the Planning Domain Definition Language (PDDL) admit action sequences guaranteed to achieve a goal state given an initial state if any are possible. Howe…
Reasoning models produce long traces of intermediate decisions and tool calls, making test-time verification increasingly important for ensuring correctness. Existing approaches either verify only the…