Among various techniques developed to foster creative thinking, brainstorming is widely used. With recent advancements in Large Language Models (LLMs), tools like ChatGPT have significantly impacted v…
We utilize recent advances in natural language processing to develop novel measures of workers’ task-level exposure to artificial intelligence (AI) and machine learning technologies from 2010 to 2023,…
Large language models (LLMs) exhibit dynamic capabilities and appear to comprehend complex and ambiguous natural language prompts. However, calibrating LLM interactions is challenging for interface de…
Existing benchmarks fall short in realism, data fidelity, agent-user interaction, and coverage across business scenarios and industries. To address these gaps, we introduce CRMArena-Pro, a novel bench…
What do real conversations with Claude tell us about the effects of AI on labor productivity? Using our privacy-preserving analysis method, we sample one hundred thousand real conversations from Claud…
Ensuring complex systems meet regulations typically requires checking the validity of assurance cases through a claim-argument-evidence framework. Some challenges in this process include the complicat…
This review explores the frontiers of large language models (LLMs) in psychological applications. Psychology has undergone several theoretical changes, and the current use of artificial intelligence (…
ABSTRACT Maintaining software packages imposes significant costs due to dependency management, bug fixes, and versioning. We show that rich method descriptions in scientific publications can serve as…
Our framework features an audio-enhanced mini-interview to capture nuanced worker desires and introduces the HumanAgency Scale (HAS) as a shared language to quantify the preferred level of human invol…
Abstract—There are a growing number of AI applications, but none tailored specifically to help residents answer their questions about municipal budget, a topic most are interested in but few have a so…
![[Pasted image 20250930085203.png]] We introduce GDPval, a benchmark evaluating AI model capabilities on realworld economically valuable tasks. GDPval covers the majority of U.S. Bureau of Labor Sta…
E-commerce search engines often rely solely on product titles as input for ranking models with latency constraints. However, this approach can result in suboptimal relevance predictions, as product ti…
This report presents the most recent findings of Microsoft’s research initiative on AI and Productivity, which seeks to measure and understand the productivity gains associated with LLM-powered produc…
Large language models (LLMs) are increasingly seen as assistants, copilots, and consultants, capable of supporting a wide range of tasks through natural conversation. However, most systems remain cons…
AI assistance produces significant productivity gains across professional domains, particularly for novice workers. Yet how this assistance affects the development of skills required to effectively su…
|_Table 1: Task Categories_ **Task Category**|**Descriptors (In your job, how important is…)**| |**Manual**|Carrying, pushing or pulling heavy objects <br><br>Working for long periods on physical acti…
Code large language models (Code LLMs) have achieved significant advancements in various code-related tasks, particularly in code generation, where the code LLMs produce the target code from natural l…
Language models are saturating benchmarks for procedural tasks with narrow objectives. But they are increasingly being deployed in long-horizon, non-stationary environments with open-ended goals. In t…
The rapid advancement of Large Language Models (LLMs) has driven novel applications across diverse domains, with LLM-based agents emerging as a crucial area of exploration. This survey presents a comp…
Abstract. Business Process Management (BPM) aims to improve organizational activities and their outcomes by managing the underlying processes. To achieve this, it is often necessary to consider inform…
We propose a taxonomy of reasoning enhancement techniques, categorized into training-time strategies (e.g., supervised fine-tuning, reinforcement learning) and test-time mechanisms (e.g., prompt engin…
A key focus is to use news headlines from the Wall Street Journal (WSJ) to predict the movement of stock prices on a daily timescale with OpenAI-based text embedding models used to create vector encod…
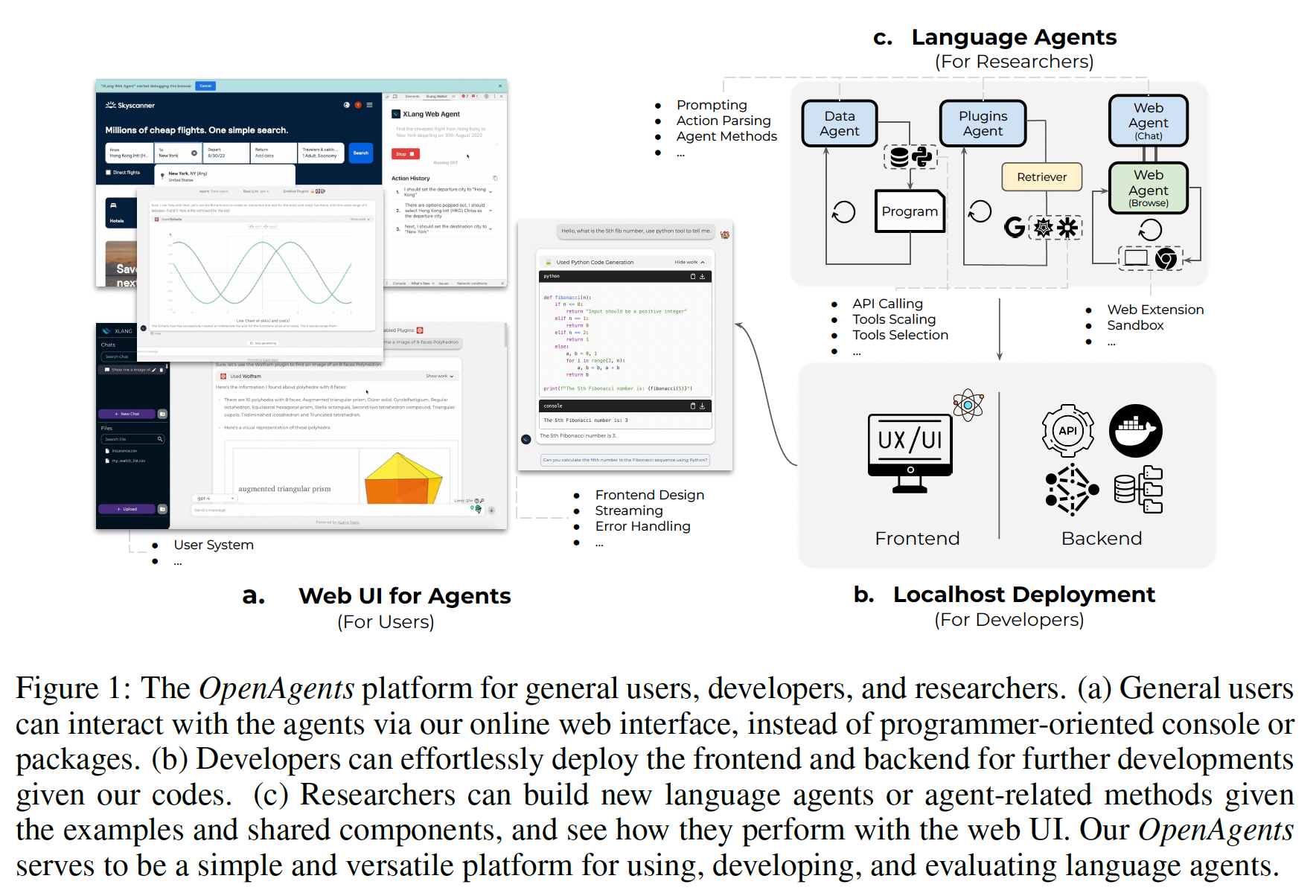 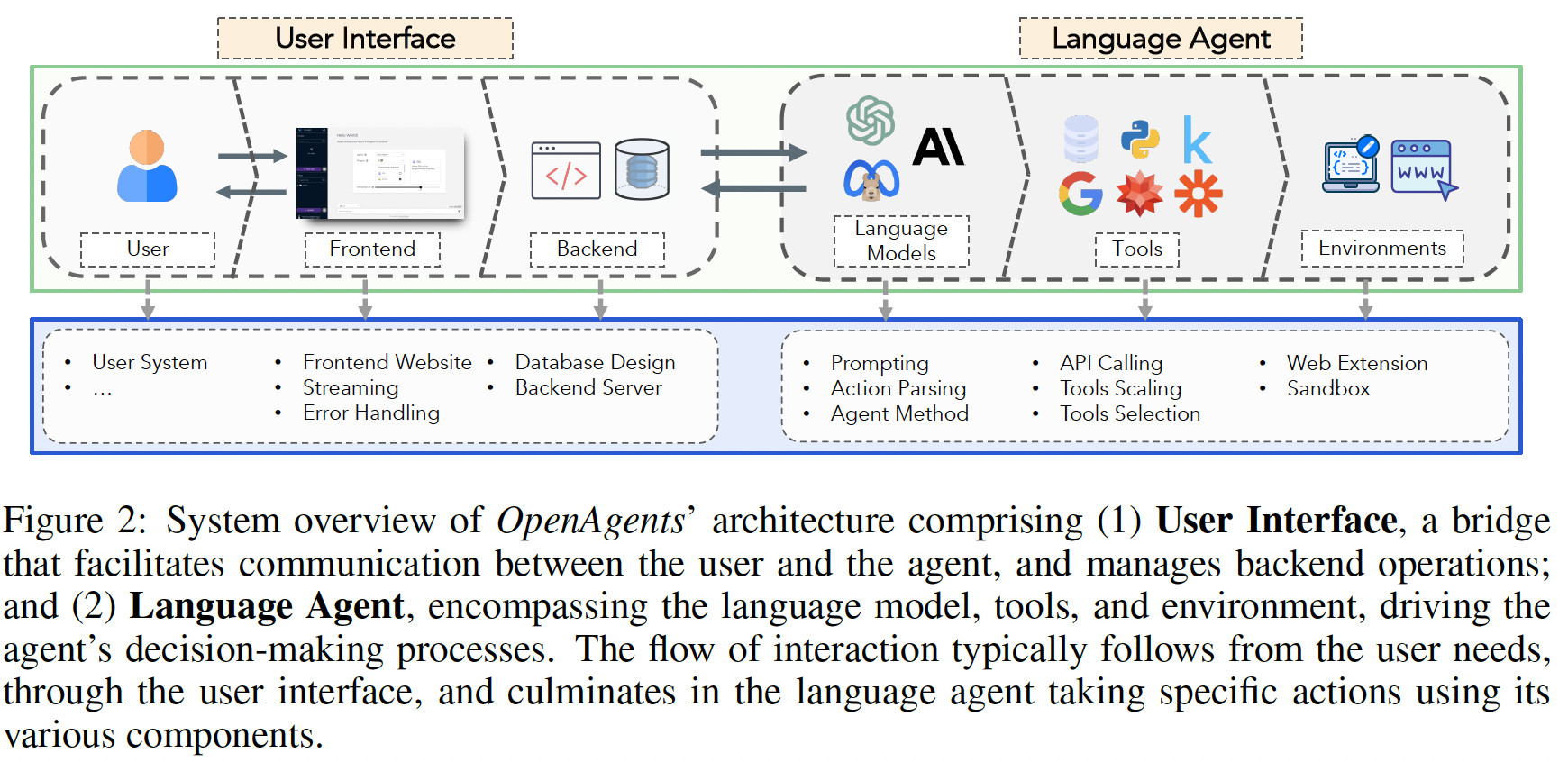 Language agents show pot…
When searching for products, the opinions of others play an important role in making informed decisions. Subjective experiences about a product can be a valuable source of information. This is also tr…
Background: Large language model systems are commonly evaluated as models, benchmarks, or short conversational episodes. Less is known about what happens when a persistent AI agent is embedded into a …
Retrieval-Augmented Generation (RAG) improves the accuracy and relevance of large language model outputs by incorporating knowledge retrieval. However, implementing RAG in enterprises poses challenges…
“There is a trending paradigm[1; 2; 3; 4; 5; 6; 7; 8] to couple large language models (LLMs) with external plugins or tools, enabling LLMs to interact with environment [9; 10] and retrieve up-to-date …
Large Language Models (LLM), conversational assistants have become prevalent for domain use cases. LLMs acquire the ability to contextual question answering through extensive training, and Retrieval A…
To address these issues, in this paper, we propose SAILER, a new Structure-Aware pre-traIned language model for LEgal case Retrieval. It is highlighted in the following three aspects: (1) SAILER fully…
People rely on social skills like conflict resolution to communicate effectively and to thrive in both work and personal life. However, practice environments for social skills are typically out of rea…
Large Language Models (LLMs) have shown promise in accelerating the scientific research pipeline. A key capability for this process is the ability to generate novel research ideas, and prior studies h…
As Bainbridge [7] noted, a key irony of automation is that by mechanising routine tasks and leaving exception-handling to the human user, you deprive the user of the routine opportunities to practice …
In this paper we develop a new survey analyzing Generative AI use in the labor market to assist in measuring the economic effects of Generative AI. We find, consistent with other surveys that Generati…
Generative artificial intelligence (AI) has the potential to both exacerbate and ameliorate existing socioeconomic inequalities. In this article, we provide a state-of-the-art interdisciplinary overvi…
The most widely deployed GPTs either codify institutional knowledge into reusable assistants or automate workflows through integrations with internal systems. Some organizations have built a culture o…
To measure the progress of these LLM agents’ performance on performing real-world professional tasks, in this paper we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that …
Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application. However, most ex…
Abstract. Factors are a foundational component of legal analysis and computational models of legal reasoning. These factor-based representations enable lawyers, judges, and AI and Law researchers to r…
Log data can reveal valuable information about how users interact with Web search services, what they want, and how satisfied they are. However, analyzing user intents in log data is not easy, especia…
This chapter explores theoretically the long-run implications of Artificial General Intelligence (AGI) for economic growth and labor markets. AGI makes it feasible to perform all economically valuable…
[[Routers]] Despite growing enthusiasm for Multi-Agent LLM Systems (MAS), their performance gains across popular benchmarks often remain minimal compared to single-agent frameworks. This gap highlig…
In this work, we take a step toward that goal by analyzing the work activities people do with AI, how successfully and broadly those activities are done, and combine that with data on what occupations…
We explore everyday co-creativity for collaborative human-AI teams in workplaces via a conversational user interface to a large language model. Previous short papers explored human-AI team-creativity …