Language as a Cognitive Tool to Imagine Goals in Curiosity-Driven Exploration
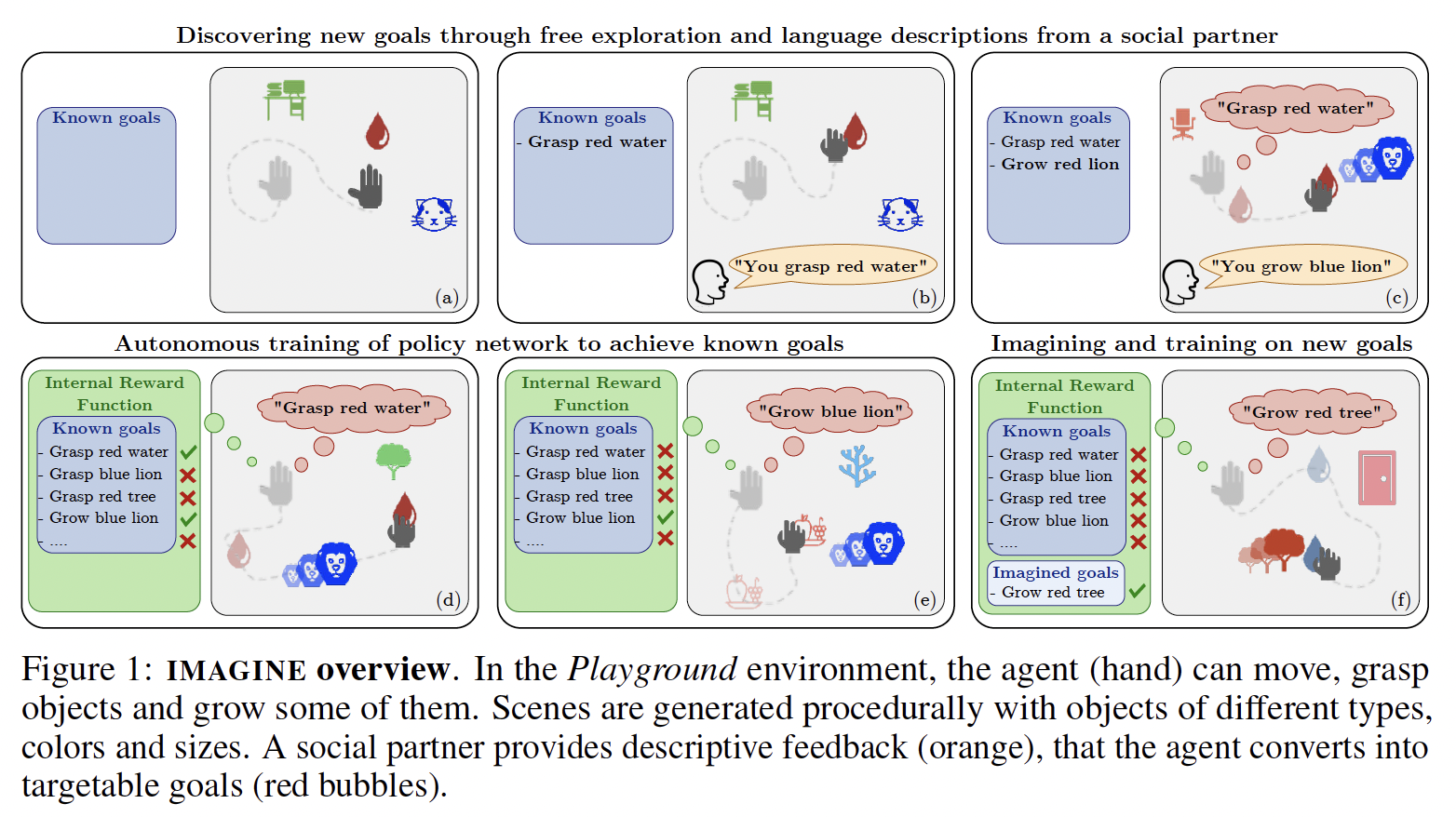
Developmental machine learning studies how artificial agents can model the way children learn open-ended repertoires of skills. Such agents need to create and represent goals, select which ones to pursue and learn to achieve them. Recent approaches have considered goal spaces that were either fixed and hand-defined or learned using generative models of states. This limited agents to sample goals within the distribution of known effects. We argue that the ability to imagine out-of-distribution goals is key to enable creative discoveries and open-ended learning. Children do so by leveraging the compositionality of language as a tool to imagine descriptions of outcomes they never experienced before, targeting them as goals during play. We introduce IMAGINE, an intrinsically motivated deep reinforcement learning architecture that models this ability. Such imaginative agents, like children, benefit from the guidance of a social peer who provides language descriptions. To take advantage of goal imagination, agents must be able to leverage these descriptions to interpret their imagined out-of-distribution goals.
Introduction. Building autonomous machines that can discover and learn open-ended skill repertoires is a longstanding goal in Artificial Intelligence. In this quest, we can draw inspiration from children development [12]. In particular, children exploration seems to be driven by intrinsically motivated brain processes that trigger spontaneous exploration for the mere purpose of experiencing novelty, surprise or learning progress [32, 42, 45]. During exploratory play, children can also invent and pursue their own problems [19]. Algorithmic models of intrinsic motivation were successfully used in developmental robotics [55, 6], in reinforcement learning [16, 63] and more recently in deep RL [8, 56]. Intrinsically Motivated Goal Exploration Processes (IMGEP), in particular, enable agents to sample and pursue their own goals without external rewards [7, 26, 27] and can be formulated within the deep RL framework [25, 53, 22, 58, 71, 60]. However, representing goal spaces and goal-achievement functions remains a major difficulty and often requires hand-crafted definitions.
Discussion / Conclusion. IMAGINE is a learning architecture that enables autonomous learning by leveraging NL interactions with a social partner. As other algorithms from the IMGEP family, IMAGINE sets its own goals and builds behavioral repertoires without external rewards. As such, it is distinct from traditional instruction-following RL agents. This is done through the joint training of a language encoder for goal representation and a goal-achievement reward function to generate internal rewards. Our proposed modular architectures with gated-attention enable efficient out-of-distribution generalization of the reward function and policy. The ability to imagine new goals by composing known ones leads to further improvements over initial generalization abilities and fosters exploration beyond the set of interactions relevant to SP. Our agent even tries to grow pieces of furniture with supplies, a behavior that can echo the way a child may try to feed his doll.