UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation
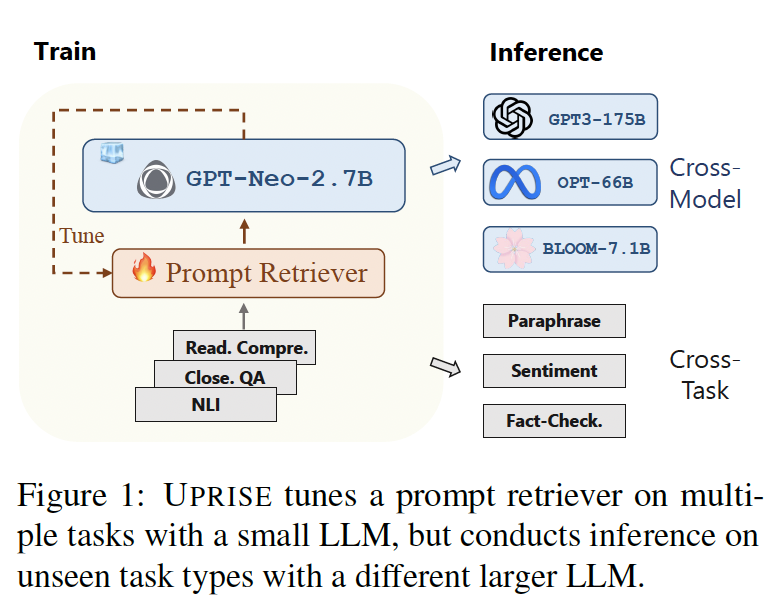
Large Language Models (LLMs) are popular for their impressive abilities, but the need for model-specific fine-tuning or task-specific prompt engineering can hinder their generalization. We propose UPRISE (Universal Prompt Retrieval for Improving zero-Shot Evaluation), which tunes a lightweight and versatile retriever that automatically retrieves prompts for a given zero-shot task input. Specifically, we demonstrate universality in a crosstask and cross-model scenario: the retriever is tuned on diverse tasks, but tested on unseen task types; we use a small frozen LLM, GPT-Neo-2.7B, for tuning the retriever, but test the retriever on different LLMs of much larger scales, such as BLOOM-7.1B, OPT-66B and GPT3-175B. Additionally, we show that UPRISE mitigates the hallucination problem in our experiments with ChatGPT, suggesting its potential to improve even the strongest LLMs. Our model and code are available at https://github.com/microsoft/LMOps.
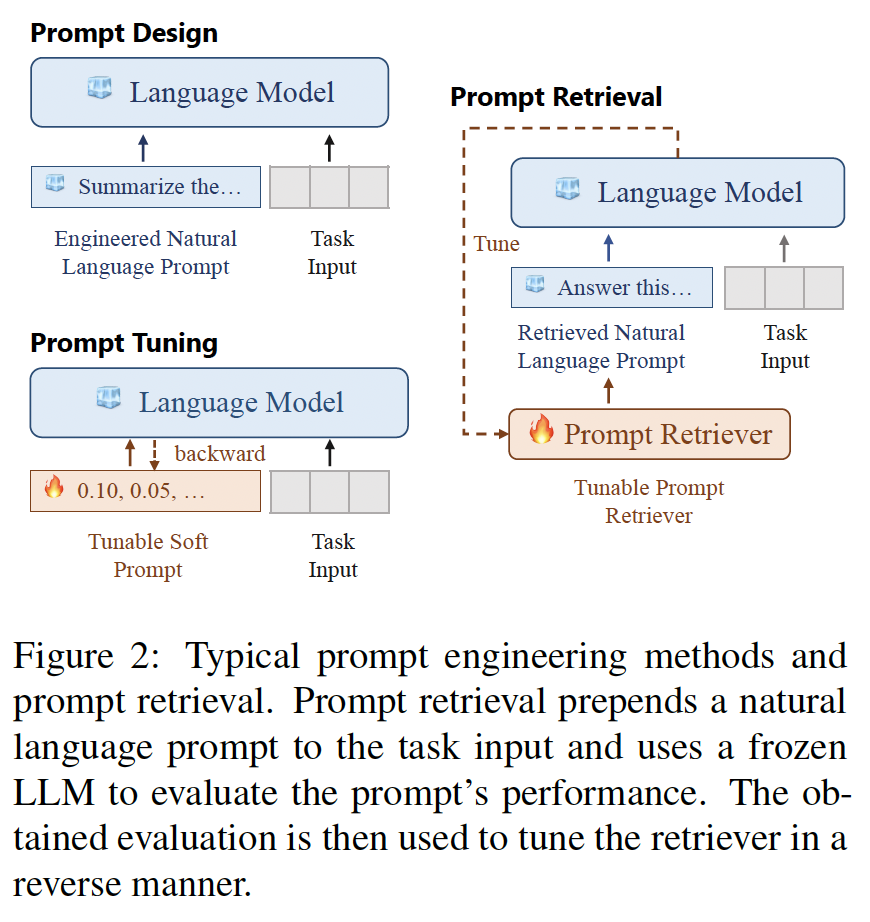
Introduction. Large Language Models (LLMs) such as GPT-3 (Brown et al., 2020), OPT (Zhang et al., 2022), and BLOOM (Scao et al., 2022) have shown impressive capabilities across a wide range of tasks. Recent research proposes two main approaches to further improve their performance: fine-tuning LLMs to follow prompts (Hu et al., 2022; Houlsby et al., 2019; Zaken et al., 2022; Wei et al., 2022a; Sanh et al., 2022) and developing prompt engineering techniques to guide the LLMs (Brown et al., 2020; Wei et al., 2022b; Liu et al., 2021; Lester et al., 2021). Fine-tuning LLMs adjusts their weights to fit specific prompts. However, this can be constrained by computational limitations or the unavailability of model weights (Hu et al., 2022). Multi-task tuning provides an alternative approach to improve zeroshot task generalization (Wei et al., 2022a; Sanh et al., 2022), which partially justifies the tuning cost. Yet, the constant evolution of LLMs creates the need for tuning new models, making the cumulative fine-tuning cost a big concern. Prompt engineering constructs prompts to guide frozen LLMs.
Discussion / Conclusion. This paper explores training a lightweight and versatile prompt retriever to improve the zero-shot performance of LLMs. We investigate the retriever’s ability to generalize from the trained task types to unseen task types, and from a small LLM to different LLMs of much larger scales. We hope our paper will spur further research on developing a universal assistant for the ever-expanding landscape of tasks and large language models. While UPRISE has shown consistent performance gains on most testing clusters, it displays limited impacts on tasks that are directly formulated as language modeling, such as Coreference Resolution and Commonsense Reasoning. Future work may explore including other formats of demonstrations such as chain-of-thought (Wei et al., 2022b) to improve the performance. Besides, the universality of UPRISE has been verified on language only in our experiment, future work may explore the versatility of UPRISE by incorporating prompts such as tool-use APIs (Schick et al., 2023), and multimodal information (Huang et al., 2023; Zhang et al., 2023).