RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
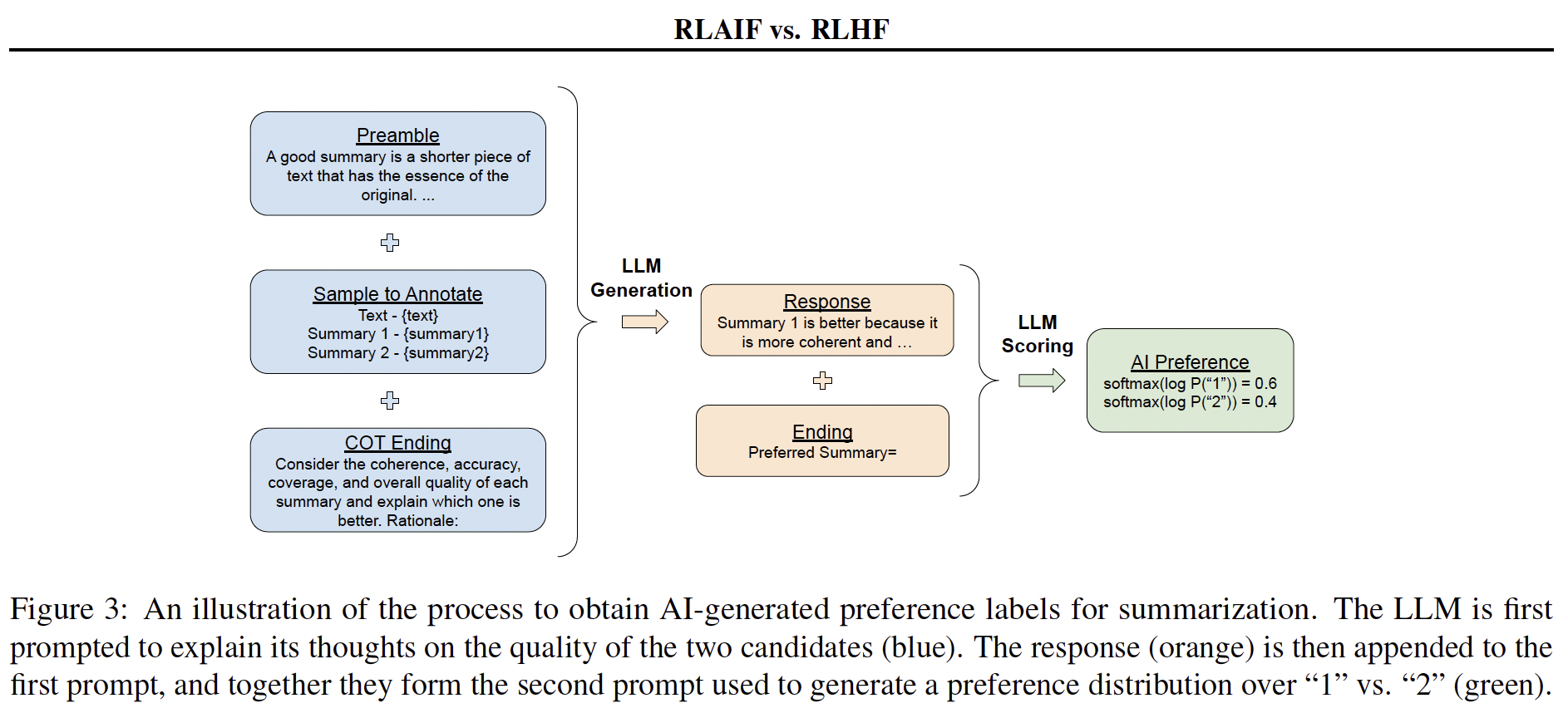
Abstract Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences, but gathering high-quality preference labels is expensive. RL from AI Feedback (RLAIF), introduced in Bai et al. (2022b), offers a promising alternative that trains the reward model (RM) on preferences generated by an off-the-shelf LLM. Across the tasks of summarization, helpful dialogue generation, and harmless dialogue generation, we show that RLAIF achieves comparable performance to RLHF. Furthermore, we take a step towards “self-improvement” by demonstrating that RLAIF can outperform a supervised finetuned baseline even when the AI labeler is the same size as the policy, or even the exact same checkpoint as the initial policy. Finally, we introduce direct-RLAIF (d-RLAIF) - a technique that circumvents RM training by obtaining rewards directly from an off-the-shelf LLM during RL, which achieves superior performance to canonical RLAIF. Our results suggest that RLAIF can achieve performance on-par with using human feedback, offering a potential solution to the scalability limitations of RLHF.
Introduction. Reinforcement Learning from Human Feedback (RLHF) is an effective technique for aligning language models to human preferences (Stiennon et al., 2020; Ouyang et al., 2022). It is cited as one of the key drivers of success in modern conversational language models, such as ChatGPT (Liu et al., 2023) and Bard (Manyika, 2023). A key advantage of
Discussion / Conclusion. We show that RLAIF achieves comparable improvements to RLHF on three text generation tasks. In head-to-head comparisons, RLAIF and RLHF are preferred at similar rates by humans. Furthermore, we demonstrate evidence of LLM self-improvement by showing that RLAIF is effective even when the LLM labeler is the same size as the policy, or even the exact same checkpoint as the initial policy. Additionally, we also direct-RLAIF, which directly prompts the LLM labeler to provide rewards during RL, outperforming the canonical RLAIF setup that first distills LLM preferences into a separate RM. Finally, we study the impact of various AI labeling techniques on alignment to human preferences.