Scaling up self-supervised learning has driven breakthroughs in language and vision, yet comparable progress has remained elusive in reinforcement learning (RL). In this paper, we study building block…
Long-context reasoning is essential for complex real-world applications, yet remains a significant challenge for Large Language Models (LLMs). Despite the rapid evolution in long-context reasoning, cu…
ABSTRACT The rapid progress of research aimed at interpreting the inner workings of advanced language models has highlighted a need for contextualizing the insights gained from years of work in this a…
To address these challenges, researchers have been exploring methods to enable RL agents to avoid catastrophic forgetting and effectively transfer knowledge, with the ultimate goal of steering the fie…
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior wor…
2 What to Scale “What to scale” refers to the specific form of TTS that is expanded or adjusted to enhance an LLM’s performance during inference. When applying TTS , researchers typically choose a sp…
Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potent…
1 Introduction Reinforcement learning (RL) has emerged as a new scaling paradigm for enhancing the capabilities of large language models (LLMs) by enabling thinking abilities [52]. Given a prompt, RL…
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR wo…
A long-term goal of language agents is to learn and improve through their own experience, ultimately outperforming humans in complex, real-world tasks. However, training agents from experience data wi…
The situated view of cognition holds that intelligent behavior depends not only on internal memory, but on an agent’s active use of environmental resources. Here, we begin formalizing this intuition w…
Despite the promising results achieved, state-of-the art interactive reinforcement learning schemes rely on passively receiving supervision signals from advisor experts, in the form of either continuo…
However, as the scale of reasoning increases, existing test-time scaling methods suffer from accumulated historical information, which not only wastes computational resources but also interferes with …
Large language models (LLMs) exhibit remarkable problem-solving abilities, but struggle with complex tasks due to static internal knowledge. Retrieval-Augmented Generation (RAG) enhances access to ext…
Large Language Models (LLMs) have demonstrated remarkable self-improvement capabilities, whereby models iteratively revise their outputs through self-generated feedback. While this reflective mechanis…
When language models (LMs) are trained via reinforcement learning (RL) to generate natural language “reasoning chains”, their performance improves on a variety of difficult question answering tasks. T…
Large language models (LLMs) demonstrate remarkable reasoning capabilities in tasks such as algorithmic coding and mathematical problem-solving. Recent methods have improved reasoning through expanded…
Recent advancements in LLM-based agents have demonstrated remarkable capabilities in handling complex, knowledge-intensive tasks by integrating external tools. Among diverse choices of tools, search t…
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful approach to enhancing the reasoning capabilities of Large Language Models (LLMs), while its mechanisms are not yet well …
Reasoning models excel in complex problem solving but exhibit a concerning tradeoff between reasoning capabilities and instruction following abilities. Existing approaches for improving instruction fo…
We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and n…
Maintaining a consistent persona is a key quality for any open domain dialogue system. Current state-of-the-art systems do this by training agents with supervised learning or online reinforcement lear…
The remarkable capability of Transformers to do reasoning and few-shot learning, without any fine-tuning, is widely conjectured to stem from their ability to implicitly simulate a multi-step algorithm…
Language models must be adapted to understand and follow user instructions. Reinforcement learning is widely used to facilitate this – typically using fixed criteria such as “helpfulness” and “harmful…
Large Language Models (LLMs) are increasingly used to simulate human users in interactive settings such as therapy, education, and social role-play. While these simulations enable scalable training an…
We then demonstrate that RL-finetuned models, even after exhibiting performance plateaus, can generate correct refinements on persistently failed problems by leveraging natural language feedback in th…
Test-time scaling such as OpenAI’s o1 [1] and DeepSeek’s R1 [2] brings a profound paradigm shift to Large Language Models (LLMs) [3–7]. Test-time scaling enables longer Chain-of-Thought thinking and i…
Deep research models perform multi-step research to produce long-form, well-attributed answers. However, most open deep research models are trained on easily verifiable short-form QA tasks via reinfor…
Reinforcement Learning has become a standard paradigm for aligning Large Language Models with human intent and task requirements. While Group Relative Policy Optimization offers an efficient, value-mo…
We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem. This allows us to draw upon the simplicity and scalability of the Transformer architecture, and asso…
Large Language Models (LLMs) have shown great potential in reasoning tasks through test-time scaling methods like self-consistency with majority voting. However, this approach often leads to diminishi…
Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually eng…
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT)…
We introduce DeepSeek-V3.2, a model that harmonizes high computational efficiency with superior reasoning and agent performance. The key technical breakthroughs of DeepSeek-V3.2 are as follows: (1) De…
Large reasoning models (LRMs) have demonstrated impressive capabilities in complex problem-solving, yet their internal reasoning mechanisms remain poorly understood. In this paper, we investigate the …
We propose DialogueReason, a reasoning paradigm that uncovers the lost roles in monologue-style reasoning models, aiming to boost diversity and coherency of the reasoning process. Recent advances in R…
Direct alignment from preferences (DAP) methods, such as DPO, have recently emerged as efficient alternatives to reinforcement learning from human feedback (RLHF), that do not require a separate rewar…
Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning performance of large language models (LLMs), particularly in mathematics and …
Reinforcement learning (RL)-based fine-tuning has become a crucial step in post-training language models for advanced mathematical reasoning and coding. Following the success of frontier reasoning mod…
Reinforcement Learning (RL) suffers from sample inefficiency in sparse reward domains, and the problem is pronounced if there are stochastic transitions. To improve the sample efficiency, reward shapi…
Recent efforts in fine-tuning language models often rely on automatic data selection, commonly using Nearest Neighbors retrieval from large datasets. However, we theoretically show that this approach …
Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaq…
Large language model (LLM) agents often struggle in environments where rules and required domain knowledge frequently change, such as regulatory compliance and user risk screening. Current approaches—…
Training Large Language Models (LLMs) to reason often relies on Reinforcement Learning (RL) with task-specific verifiers. However, many real-world reasoning-intensive tasks lack verifiers, despite off…
Process Reward Models (PRMs) have emerged as a promising framework for supervising intermediate reasoning in large language models (LLMs), yet existing PRMs are primarily trained on general or Science…
This paper proposes a query-level meta-agent named FLOWREASONER to automate the design of query-level multi-agent systems, i.e., one system per user query. Our core idea is to incentivize a reasoning-…
The main part of BERT models is a multi-layer Transformer network. A Transformer layer consists of a self-attention sub-layer and an FFN sub-layer. Both of them follow the post-norm architecture: outp…
Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). Unlike traditional RL approaches, RLV…
Recent advancements in Large Language Models (LLMs) have shown that it is promising to utilize Process Reward Models (PRMs) as verifiers to enhance the performance of LLMs. However, current PRMs face …
Meta-learning shows particular promise for reinforcement learning (RL), where algorithms are often adapted from supervised or unsupervised learning despite their suboptimality for RL. However, until n…
we improve the effectiveness of the reward model by introducing a penalty term on the reward, named contrastive rewards. Our approach involves two steps: (1) an offline sampling step to obtain respons…
Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that p…
A generalizable reward model is crucial in Reinforcement Learning from Human Feedback (RLHF) as it enables correctly evaluating unseen prompt-response pairs. However, existing reward models can lack t…
Large Language Models (LLMs) were shown to struggle with long-term planning, which may be caused by the limited way in which they explore the space of possible solutions. We propose an architecture wh…
How can we train agents to navigate uncertainty over long horizons? In this work, we propose ΔBelief-RL, which leverages a language model's own intrinsic beliefs to reward intermediate progress. Our m…
Reinforcement Learning from Human Feedback (RLHF) has proven effective in aligning large language models with human intentions, yet it often relies on complex methodologies like Proximal Policy Optimi…
The progress of AI is bottlenecked by the quality of evaluation, and powerful LLM-as-a-Judge models have proved to be a core solution. Improved judgment ability is enabled by stronger chain-of-thought…
Post-training of Large Language Models (LMs) often prioritizes accuracy and helpfulness at the expense of diversity. This creates a tension: while post-training improves response quality, it also shar…
We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Althoug…
Some policy gradient approaches are explained below: Policy Gradient (REINFORCE). The REINFORCE algorithm [114, 115] is a method used to improve decision-making by adjusting the model’s strategy (poli…
Large reasoning models (LRMs) tackle complex reasoning problems by following long chain-ofthoughts (Long CoT) that incorporate reflection, backtracking, and self-validation. However, the training tech…
The success of Large Language Models (LLMs) has sparked interest in various agentic applications. A key hypothesis is that LLMs, leveraging common sense and Chain-of-Thought (CoT) reasoning, can effec…
Large Language Models (LLMs) are increasingly being used to assess the relevance of information objects. This work reports on experiments to study the labelling of short texts (i.e., passages) for rel…
After the pretraining stage of LLMs, techniques such as SFT, RLHF, RLVR, and RFT are applied to enhance instruction-following ability, mitigate undesired responses, improve reasoning capability and en…
Abstract—Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs’ abil…
As everyday use cases of large language model (LLM) AI assistants have expanded, it is becoming increasingly important to personalize responses to align to different users’ preferences and goals. Whil…
How can we use AI to discover a new state of the art for a scientific problem? Prior work in test-time scaling, such as AlphaEvolve, performs search by prompting a frozen LLM. We perform reinforcement…
Large language models (LLMs) often struggle to learn from corrective feedback within a conversational context. They are rarely proactive in soliciting this feedback, even when faced with ambiguity, wh…
Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning c…
Large language models (LLMs) are trained for downstream tasks by updating their parameters (e.g., via RL). However, updating parameters forces them to absorb task-specific information, which can resul…
Creating reinforcement learning (RL) agents that are capable of accepting and leveraging task specific knowledge from humans has been long identified as a possible strategy for developing scalable app…
Language models (LMs) may lead their users to make suboptimal downstream decisions when they confidently hallucinate. This issue can be mitigated by having the LM verbally convey the probability that …
Multimodal Large Language Models (MLLMs) rely on continual instruction tuning to adapt to the evolving demands of real-world applications. However, progress in this area is hindered by the lack of rig…
Reinforcement Learning from Human Feedback (RLHF) aligns language models to human preferences by employing a singular reward model derived from preference data. However, such an approach overlooks the…
RLHF assumes that annotation responses reflect genuine human preferences. We argue this assumption warrants systematic examination, and that behavioral science offers frameworks that bring clarity to …
Large Reasoning Models (LRMs) have significantly enhanced their capabilities in complex problem-solving by introducing a thinking draft that enables multipath Chain-of-Thought explorations before prod…
Recent work has shown that LLMs can sometimes detect when steering vectors are injected into their residual stream and identify the injected concept—a phenomenon termed “introspective awareness.” We i…
Reinforcement Learning with Verifiable Reward (RLVR) is empirically shown to notably enhance the reasoning performance of large language models (LLMs), particularly in mathematics and programming. How…
We propose a taxonomy of reasoning enhancement techniques, categorized into training-time strategies (e.g., supervised fine-tuning, reinforcement learning) and test-time mechanisms (e.g., prompt engin…
To address these issues, we introduce Meta- Reasoner, a framework that dynamically optimizes inference-time reasoning by enabling LLMs to “think about how to think.” Drawing inspiration from human met…
Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et a…
Large language model (LLM) agents have rapidly emerged as powerful assistants for complex, multi-step tasks, yet agents deployed in the wild remain largely static, trained once and served unchanged re…
Large Language Models (LLMs) have demonstrated significant improvements in reasoning capabilities through supervised fine-tuning and reinforcement learning. However, when training reasoning models, th…
We show that when large language models learn to reward hack on production RL environments, this can result in egregious emergent misalignment. We start with a pretrained model, impart knowledge of re…
AI agents increasingly operate over extended time horizons, yet their ability to retain, organize, and recall multimodal experiences remains a critical bottleneck. Building effective lifelong memory r…
The pursuit of general-purpose artificial intelligence depends on large language models (LLMs) that can handle both structured reasoning and open-ended generation. We present OMNI-THINKER, a unified r…
Reinforcement learning (RL) with outcome-based rewards has achieved significant success in training large language model (LLM) agents for complex reasoning tasks. However, in active reasoning where ag…
Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) are two prominent post-training paradigms for refining the capabilities and aligning the behavior of Large Language Models (LLMs). Existing…
Automatically synthesizing dense rewards from natural language descriptions is a promising paradigm in reinforcement learning (RL), with applications to sparse reward problems, open-ended exploration,…
Every agent interaction generates a next-state signal, namely the user reply, tool output, terminal or GUI state change that follows each action, yet no existing agentic RL system recovers it as a liv…
OpenAI’s recent introduction of Reinforcement Fine-Tuning (RFT) showcases the potential of reasoning foundation model and offers a new paradigm for fine-tuning beyond simple pattern imitation. This te…
posttraining process equips these models with the ability to output long chains of thought, or "thinking tokens," during inference time, which can guide the model toward the correct answer. Yet, the c…
Many AI applications of interest require specialized multi-modal models. Yet, relevant data for training these models is inherently scarce. Human annotation is prohibitively expensive, error-prone, an…
Reinforcement learning (RL) has emerged as a powerful method for improving the reasoning abilities of large language models (LLMs). Outcome-based RL, which rewards policies solely for the correctness …
Reinforcement learning for LLM reasoning has rapidly emerged as a prominent research area, marked by a significant surge in related studies on both algorithmic innovations and practical applications. …
we propose Personalized-RLHF (P-RLHF), an efficient framework that utilizes a lightweight user model to capture individual user preferences and jointly learns the user model and the personalized LLM f…
However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF fram…
In proactive dialogue, the challenge lies not just in generating responses but in steering conversations toward predetermined goals, a task where Large Language Models (LLMs) typically struggle due to…
Large Language Models (LLMs) often produce plausible but poorly-calibrated answers, limiting their reliability on reasoning-intensive tasks. We present Reinforcement Learning from Self- Feedback (RLSF…
We offer a novel perspective on reward modeling by formulating it as a policy discriminator, which quantifies the difference between two policies to generate a reward signal, guiding the training poli…
Mimicking human behavior to actively learning from general experience and achieve artificial general intelligence has always been a human dream. Recent reinforcement learning (RL) based large-thinking…
it remains contentious whether RL truly expands a model’s reasoning capabilities or merely amplifies high-reward outputs already latent in the base model’s distribution, and whether continually scalin…
Step-by-step verifiers—also known as process reward models (PRMs)—are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to bui…
We introduce a Reinforcement Learning Psychotherapy AI Companion that generates topic recommendations for therapists based on patient responses. The system uses Deep Reinforcement Learning (DRL) to ge…
Self-evolving Large Language Models (LLMs) offer a scalable path toward superintelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for t…
What if artificial intelligence could not only solve problems for which it was trained but also learn to teach itself to solve new problems (i.e., metalearn)? In this study, we demonstrate that a pre-…
Large language models (LLMs) are typically trained by reinforcement learning (RL) with verifiable rewards (RLVR) and supervised fine-tuning (SFT) on reasoning traces to improve their reasoning abiliti…
Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent cap…
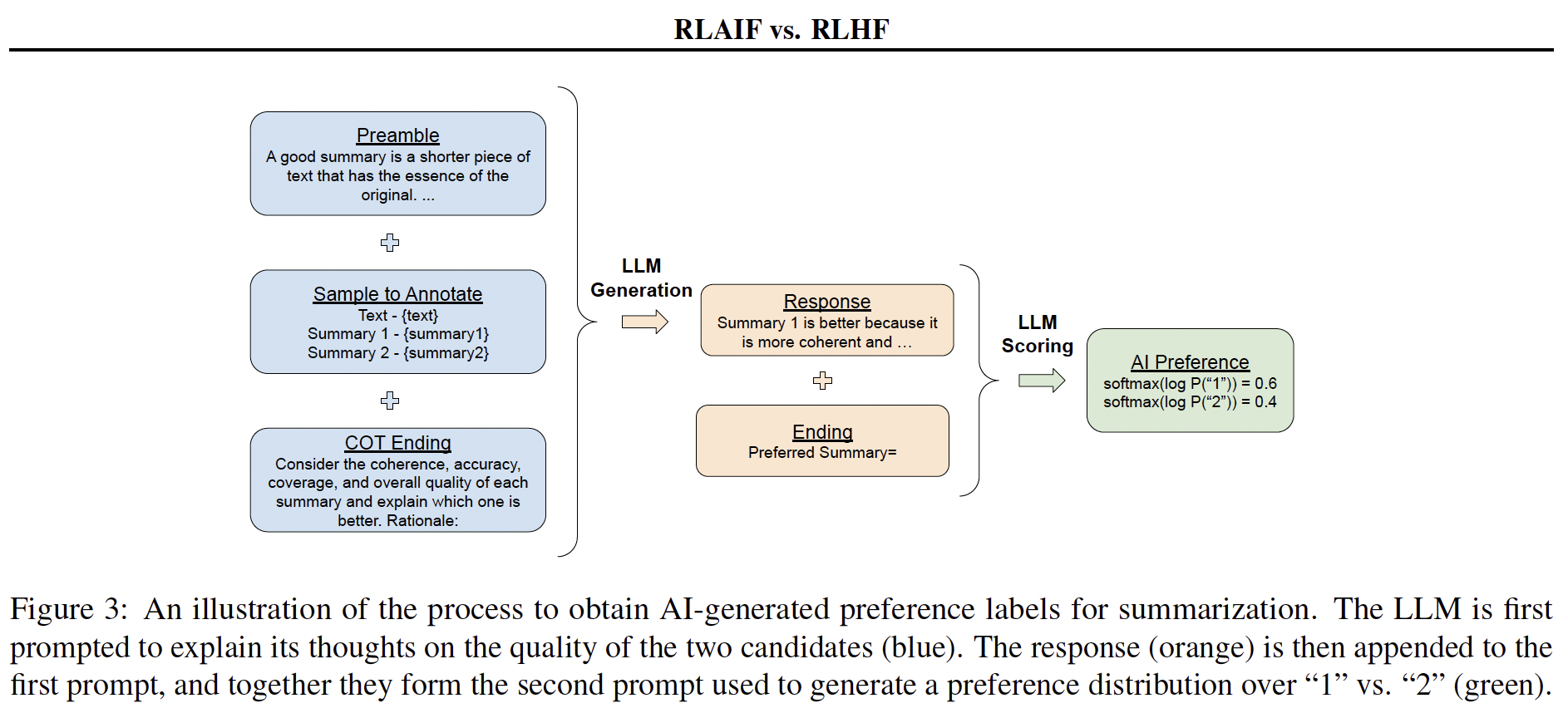 Abstract Reinforcement learning from human feedback (RLHF) has proven effec…
We present the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF) in this technical report, which is widely reported to outperform its offline counterpart by a large margin…
This paper introduces RLNVR (Reinforcement Learning from Non-Verified Rewards), a framework for training language models using noisy, real-world feedback signals without requiring explicit human verif…
The dominant paradigm for training large reasoning models starts with pre-training using next-token prediction loss on vast amounts of data. Reinforcement learning, while powerful in scaling reasoning…
Reinforcement Learning with Verifiable Rewards (RLVR) demonstrates promising potential in advancing the reasoning capabilities of LLMs. However, its success remains largely confined to mathematical an…
We propose ReSearch, a novel framework that trains LLMs to Reason with Search via reinforcement learning without using any supervised data on reasoning steps. Our approach treats search operations as …
AI agents are artificial intelligence systems capable of observing and taking actions in an environment. As adoption spreads across industries, there is a growing need for AI agents to quickly learn d…
With the growing adoption of large language model agents in persistent real-world roles, they naturally encounter continuous streams of tasks. A key limitation, however, is their failure to learn from…
We propose Rec-R1, a general reinforcement learning framework that bridges large language models (LLMs) with recommendation systems through closed-loop optimization. Unlike prompting and supervised fi…
it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive mo…
Large Language Models (LLMs) show potential as sequential decision-making agents, but their application is often limited due to a reliance on large, computationally expensive models. This creates a ne…
Reinforcement learning (RL) yields substantial improvements in large language models’ (LLMs) downstream task performance and alignment with human values. Surprisingly, such large gains result from upd…
In the context of large language models (LLMs), recent work by Guo et al. proposed a unified model whereby System 2 type “thinking” emerged as a consequence of model-free RL applied to solve mathemati…
Large Language Models (LLM), conversational assistants have become prevalent for domain use cases. LLMs acquire the ability to contextual question answering through extensive training, and Retrieval A…
Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RL…
Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing Large Language Models (LLMs), exemplified by the success of OpenAI’s o-series. In RLVR, rewards a…
Introduction. Reinforcement learning or RL is a class of methods for solving various kinds of sequential decision making tasks. In such tasks, we want to design an agent that interacts with an externa…
In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a rea…
The recent paradigm shift towards training large language models (LLMs) using DeepSeek-R1-Zero-style reinforcement learning (RL) on verifiable rewards has led to impressive advancements in code and ma…
Reasoning training incentivizes LLMs to produce long chains of thought (long CoT), which among other things, allows them to explore solution strategies with self-checking. This results in higher accur…
This technical report details a novel approach to combining reasoning and retrieval augmented generation (RAG) within a single, lean language model architecture. While existing RAG systems typically r…
Large language models (LLMs) have recently demonstrated remarkable progress in reasoning capabilities through reinforcement learning with verifiable rewards (RLVR). By leveraging simple rule-based rew…
The advent of test-time scaling in large language models (LLMs), exemplified by OpenAI’s o1 series, has advanced reasoning capabilities by scaling computational resource allocation during inference. W…
Reward models play a critical role in guiding large language models toward outputs that align with human expectations. However, an open challenge remains in effectively utilizing test-time compute to …
Reward models (RMs) are at the crux of successfully using RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those models. E…
We consider the problem of multi-objective alignment of foundation models with human preferences, which is a critical step towards helpful and harmless AI systems. However, it is generally costly and …
Reinforcement Learning (RL) has been shown to improve the capabilities of large language models (LLMs). However, applying RL to open-domain tasks faces two key challenges: (1) the inherent subjectivit…
Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their respective role in enhancing model generalization in rule-ba…
We investigate the potential of large language models (LLMs) to serve as efficient simulators for agentic search tasks in reinforcement learning (RL), thereby reducing dependence on costly interaction…
Large language models trained with reinforcement learning with verifiable rewards tend to trade accuracy for length—inflating response lengths to achieve gains in accuracy. While longer answers may be…
Scaling the number of parameters and the size of training data has proven to be an effective strategy for improving large language model (LLM) performance. Yet, as these models grow increasingly power…
Model steering represents a powerful technique that dynamically aligns large language models (LLMs) with human preferences during inference. However, conventional model-steering methods rely heavily o…
While Large Language Models (LLMs) excel at generating human-like text, aligning their outputs with complex, qualitative goals like pedagogical soundness remains a significant challenge. Standard rein…
Direct Preference Optimization (DPO) is a widely used offline preference optimization algorithm that reparameterizes reward functions in reinforcement learning from human feedback (RLHF) to enhance si…
LLM-based agents are increasingly deployed to handle streaming tasks, yet they often remain one-off problem solvers that fail to learn from past interactions. Reusable skills distilled from experience…
Large Language Model (LLM) agents have shown stunning results in complex tasks, yet they often operate in isolation, failing to learn from past experiences. Existing memory-based methods primarily sto…
Large Language Models (LLMs) have achieved impressive success across a wide range of reasoning tasks, particularly when enhanced with Chain-of-Thought (CoT) prompting, where models generate intermedia…
Large Language Models (LLMs) have delivered impressive results in language understanding, generation, reasoning, and pushes the ability boundary of multimodal models. Transformer models, as the founda…
Abstract As a paradigm for sequential decision making in unknown environments, reinforcement learning (RL) has received a flurry of attention in recent years. However, the explosion of model complexit…
 Model alignment with human preferences is an essential step in making Large Lang…
As models increasingly leverage multi-step reasoning strategies to solve complex problems, supervising the logical validity of these intermediate steps has become a critical research challenge. Proces…
Large transformer models trained on diverse datasets have shown a remarkable ability to learn in-context, achieving high few-shot performance on tasks they were not explicitly trained to solve. In thi…
Large Language Models (LLMs) often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correc…
Despite the remarkable capabilities of large language models, current training paradigms inadvertently foster sycophancy, i.e., the tendency of a model to agree with or reinforce user-provided informa…
This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during i…
In this work, we propose a novel framework that integrates large language models (LLMs) with an RL-based dialogue manager for open-ended dialogue with a specific goal. By leveraging hierarchical reinf…
We present TarGEN, a multi-step prompting strategy for generating high-quality synthetic datasets using LLMs. An advantage of TarGEN is its seedless nature; it does not require specific task instances…
[**https://arxiv.org/abs/2403.04642**](https://arxiv.org/abs/2403.04642) [[Reinforcement Learning]] Reinforcement Learning from Human Feedback (RLHF) has emerged as a dominant approach for aligning …
Self-Rewarding Language Models propose an architecture in which the Large Language Models(LLMs) both generates responses and evaluates its own outputs via LLM-as-a-Judge prompting, dynamically improvi…
We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3- mini’s performance via the new Reflective Generative Form. The new form focuses on highquality reasoning traje…
This paper aims to overcome a major obstacle in scaling reinforcement learning (RL) for reasoning with large language models (LLMs), namely the collapse of policy entropy. Such phenomenon is consisten…
The emergence of agentic reinforcement learning (Agentic RL) marks a paradigm shift from conventional reinforcement learning applied to large language models (LLM RL), reframing LLMs from passive sequ…
Reinforcement learning with verifiable rewards (RLVR) is a promising approach for training language models (LMs) on reasoning tasks that elicit emergent long chains of thought (CoTs). Unlike supervise…
Large language models (LLMs) excel at complex reasoning tasks such as mathematics and coding, yet they frequently struggle with simple interactive tasks that young children perform effortlessly. This …
Abstract: The current paradigm of test-time scaling relies on generating long reasoning traces (“thinking” more) before producing a response. In agent problems that require interaction, this can be do…
Recent work on enhancing the reasoning abilities of large language models (LLMs) has introduced explicit length control as a means of constraining computational cost while preserving accuracy. However…
The core challenge in applying RL to complex reasoning is to identify a sequence of actions that result in positive rewards and provide appropriate supervision for optimization. Outcome supervision pr…
Research on applications of Reinforcement Learning (RL) to Large Language Models (LLMs) has mostly been focused on single-turn problems, such as mathematical reasoning or single-shot code generation. …
Making language models bigger does not inherently make them better at following a user’s intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpf…
Recent advances in Large Language Model (LLM) agents have demonstrated their promising general capabilities. However, their performance in specialized real-world domains often degrades due to challeng…
Recent advances in reinforcement learning (RL) have significantly enhanced the agentic capabilities of large language models (LLMs). In long-term and multi-turn agent tasks, existing approaches driven…
Reinforcement learning (RL) with tree search has demonstrated superior performance in traditional reasoning tasks. Compared to conventional independent chain sampling strategies with outcome supervisi…
While large language models (LLMs) have demonstrated strong performance on factoid question answering, they are still prone to hallucination and untruthful responses, particularly when tasks demand in…
Large Language Models (LLMs) have shown remarkable capabilities through two complementary paradigms: Retrieval-Augmented Generation (RAG), which enhances knowledge grounding, and Reinforcement Learnin…
Abstract: We study why Tool-Integrated Reasoning (TIR) makes Large Language Models (LLMs) more capable. While LLMs integrated with tools like Python code interpreters show great promise, a principled …
Long chains of thought (CoT) from current language models frequently contain logical gaps and unjustified leaps, limiting the gains from additional test-time compute. Improving reasoning quality direc…
Once language models (LMs) are deployed, they can interact with users long-term, ideally evolving continuously based on their feedback. Asking for direct user feedback can be disruptive; thus, we stud…
Language models must now generalize out of the box to novel environments and work inside inference-scaling search procedures, such as AlphaEvolve, that select rollouts with a variety of task-specific …
Large Language Models (LLMs) employ Chain-of-Thought (CoT) reasoning to deconstruct complex problems. While longer CoTs are often presumed superior, this paper challenges that notion, arguing that lon…
Larger models learn tasks smaller models do not. What drives this phenomenon? We develop a simple phenomenological argument that power-law scaling already suggests that a larger model will be able to …
Reinforcement learning with verifiable rewards (RLVR) has facilitated significant advances in large language models (LLMs), particularly for reasoning tasks with objective, ground-truth answers, such …
Effective information searching is essential for enhancing the reasoning and generation capabilities of large language models (LLMs). Recent research has explored using reinforcement learning (RL) to …
We introduce rStar2-Agent, a 14B math reasoning model trained with agentic reinforcement learning to achieve frontier-level performance. Beyond current long CoT, the model demonstrates advanced cognit…