Latent Skill Discovery for Chain-of-Thought Reasoning
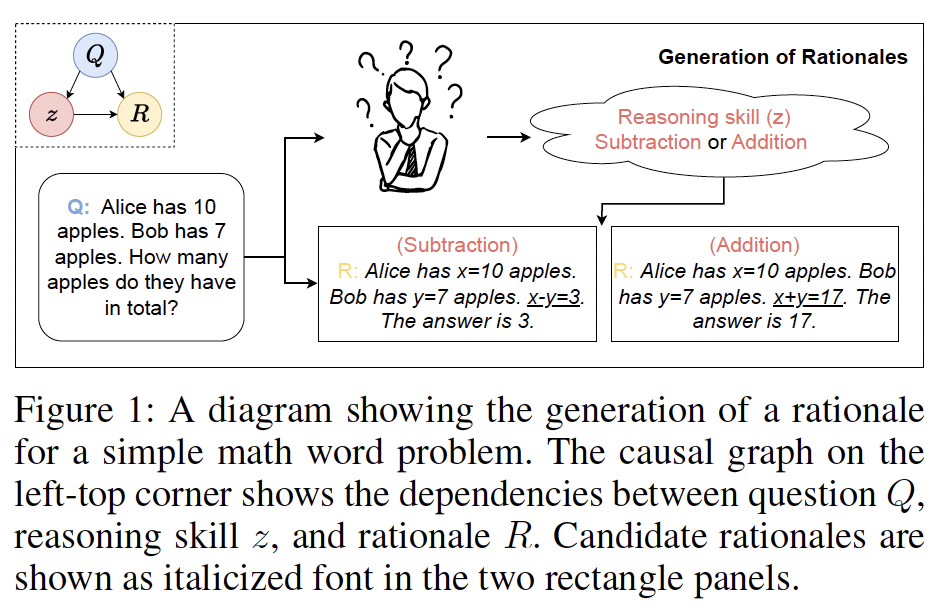
Recent advances in Large Language Models (LLMs) have led to an emergent ability of chain-of-thought (CoT) prompting, a prompt reasoning strategy that adds intermediate rationale steps between questions and answers to construct prompts. Conditioned on these prompts, LLMs can effectively learn in context to generate rationales that lead to more accurate answers than when answering the same question directly. To design LLM prompts, one important setting, called demonstration selection, considers selecting demonstrations from an example bank. Existing methods use various heuristics for this selection, but for CoT prompting, which involves unique rationales, it is essential to base the selection upon the intrinsic skills that CoT rationales need, for instance, the skills of addition or subtraction for math word problems. To address this requirement, we introduce a novel approach named Reasoning Skill Discovery (RSD) that use unsupervised learning to create a latent space representation of rationales, called a reasoning skill. Simultaneously, RSD learns a reasoning policy to determine the required reasoning skill for a given question. This can then guide the selection of examples that demonstrate the required reasoning skills.
Introduction. The Large Language Model (LLMs) exhibit remarkable capabilities in solving various downstream tasks through incontext learning (ICL) (Brown et al. 2020), even without being explicitly trained on the distribution of in-context examples (Vaswani et al. 2017; Devlin et al. 2019; Rae et al. 2021; Chowdhery et al. 2022; Wei et al. 2022a). Using incontext learning, LLMs generate output for an input query by conditioning on a prompt that contains a few input-output demonstrations 1.
Discussion / Conclusion. This paper introduces RSD, a novel demonstration selection method designed for CoT prompting. RSD bases the selection on reasoning skills, which are latent representations discovered by unsupervised learning from rationales via a CVAE. The effectiveness of RSD is empirically supported by the experiments conducted across four LLMs and over four different reasoning tasks. Despite the success of RSD, a few limitations and potential future directions are worth noting. First, the impact of