Large Language Models (LLMs) demonstrate remarkable performance in semantic understanding and generation, yet accurately assessing their output reliability remains a significant challenge. While numer…
Abstract—Diffusion Language Models (DLMs) are rapidly emerging as a powerful and promising alternative to the dominant autoregressive (AR) paradigm. By generating tokens in parallel through an iterati…
Large language models (LLMs) excel at complex reasoning when they include intermediate steps, known as chains of thought (CoTs). However, these rationales are often overly verbose, even for simple pro…
We introduce EURUS, a suite of large language models (LLMs) optimized for reasoning. Finetuned from Mistral-7B and CodeLlama-70B, EURUS models achieve state-of-the-art results among open-source models…
Can LLM agents explore codebases and reason about code semantics without executing the code? We study this capability, which we call agentic code reasoning, and introduce semi-formal reasoning: a stru…
Bilgehan Sel, Ahmad Al-Tawaha, Vanshaj Khattar, Lu Wang, Ruoxi Jia and Ming Jin Virginia Tech, Microsoft “Current literature, aiming to surpass the “Chain-of-Thought” approach, often resorts to an ex…
 Modern systems for multi-hop question answering (QA) typically break questi…
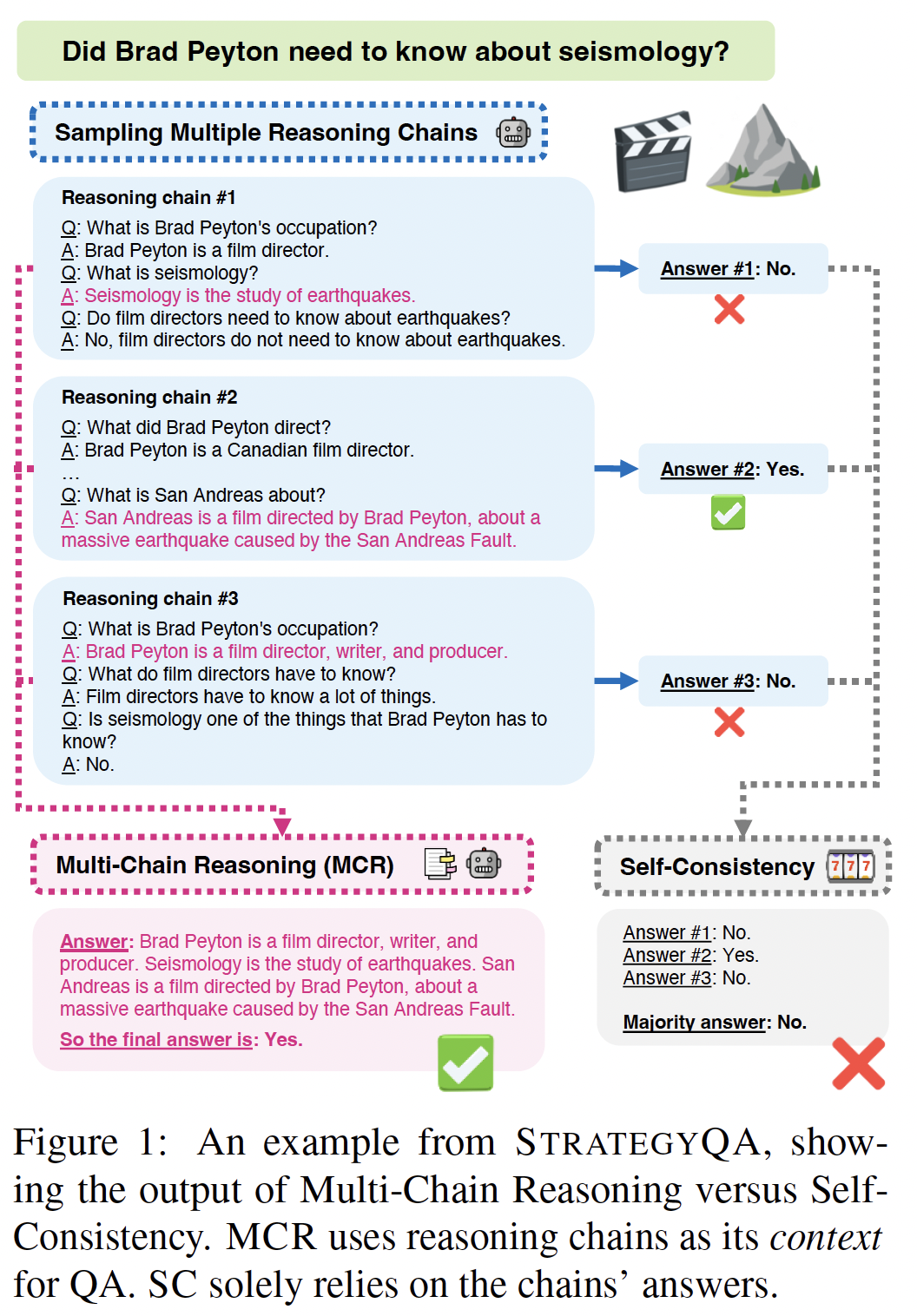
“The recent success in large language models (LLMs) has shown that properly prompted LLMs demonstrate emergent capabilities on complex understanding and question-answering tasks (Wei et al., 2022a). E…
Why do thinking language models like DeepSeek R1 outperform their base counterparts? Despite consistent performance gains, it remains unclear to what extent thinking models learn entirely new reasonin…
Existing research indicates that the output of Chain-of-Thought (CoT) is significantly affected by input perturbations. Although many methods aim to mitigate such impact by optimizing prompts, a theor…
Recent advancements in Chain-of-Thought (CoT) reasoning utilize complex modules but are hampered by high token consumption, limited applicability, and challenges in reproducibility. This paper conduct…
Large Language Models (LLMs) have achieved notable performance across a wide range of natural language understanding and generation tasks, from open-ended dialogue and code synthesis to mathematical r…
In this work, we propose Chain of Draft (CoD), a novel paradigm inspired by human cognitive processes, where LLMs generate minimalistic yet informative intermediate reasoning outputs while solving tas…
Large Language Models (LLMs) have made notable progress in mathematical reasoning, yet they often rely on single-paradigm reasoning that limits their effectiveness across diverse tasks. In this paper,…
This paper introduces an approach for training o1-like RAG models that retrieve and reason over relevant information step by step before generating the final answer. Conventional RAG methods usually p…
we argue that CoT rationales can be misleading and are neither necessary nor sufficient for trustworthy interpretability By analysing faithfulness in terms of whether CoTs are not only human-interpret…
In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) promptin…
Large language models have astounded the world with fascinating new capabilities. However, they currently lack the ability to teach themselves new skills, relying instead on large amounts of human-gen…
Chain-of-Thought (CoT) does not elicit genuine, abstract reasoning. Instead, we argue that Chain-of- Thought (CoT) functions as a powerful structural constraint that guides Large Language Models (LLMs…
Narrative comprehension on long stories and novels has been a challenging domain attributed to their intricate plotlines and entangled, often evolving relations among characters and entities. Given th…
We show that reinforcement learning applied to large language models (LLMs) significantly boosts performance on complex coding and reasoning tasks. Additionally, we compare two general-purpose reasoni…
Large language models [Touvron et al., 2023, Anil et al., 2023, Achiam et al., 2023] are increasingly used to perform logical reasoning and other problems that require algorithmic thinking. To underst…
Despite the recent advancements in language models (LMs), their ability to solve complex problems remains limited. This paper introduces Cumulative Reasoning (CR), a novel approach that utilizes LMs c…
While large language models (LLMs) leverage both knowledge and reasoning during inference, the capacity to distinguish between them plays a pivotal role in model analysis, interpretability, and develo…
Large reasoning models have demonstrated strong problem-solving abilities, yet real-world tasks often require external tools and long-horizon interactions. Existing agent frameworks typically follow p…
The field of natural language processing (NLP) has witnessed significant progress in recent years, with a notable focus on improving large language models’ (LLM) performance through innovative prompti…
Large reasoning models (LRMs) have demonstrated impressive capabilities in complex problem-solving, yet their internal reasoning mechanisms remain poorly understood. In this paper, we investigate the …
One of the major barriers to using large language models (LLMs) in medicine is the perception they use uninterpretable methods to make clinical decisions that are inherently different from the cogniti…
Reinforcement learning (RL) training of large language models (LLMs) on unverifiable tasks is challenging even when a reasonable-quality reference answer is available. We propose a constrained RL trai…
Indeed, a growing number of researchers have proposed that current LLMs are unable to generalize causal ideas beyond their training distribution and/or without strong user-induced guidance (e.g., chai…
Large Reasoning Models (LRMs) have shown remarkable reasoning capabilities, yet they often suffer from overthinking, expending redundant computational steps on simple problems, or underthinking, faili…
Large language models (LLMs) have demonstrated remarkable proficiency in generating detailed and coherent explanations of complex concepts. However, the extent to which these models truly comprehend t…
Large Language Models (LLMs) have shown remarkable abilities across various language tasks, but solving complex reasoning problems remains a challenge. While existing methods like Chainof-Thought (CoT…
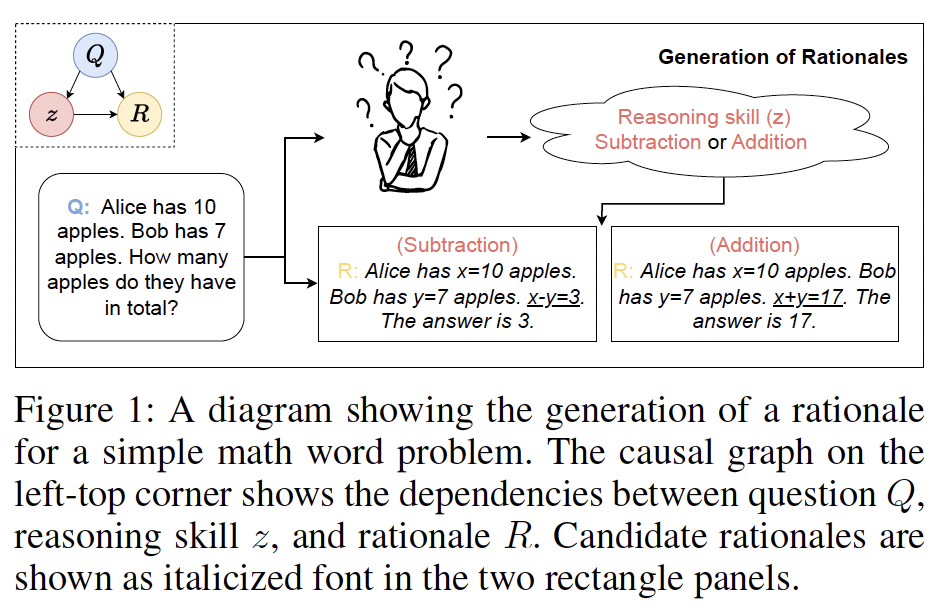
When leveraging language models for reasoning tasks, generating explicit chainof- thought (CoT) steps often proves essential for achieving high accuracy in final outputs. In this paper, we investigate…
While existing benchmarks probe the reasoning abilities of large language models (LLMs) across diverse domains, they predominantly assess passive reasoning, providing models with all the information n…
The emergence of reasoning models and their integration into practical AI chat bots has led to breakthroughs in solving advanced math, deep search, and extractive question answering problems that requ…
To augment language models with the ability to reason, researchers usually prompt or finetune them to produce chain of thought reasoning steps before producing the final answer. However, although peop…
Large Language Models (LLMs) were shown to struggle with long-term planning, which may be caused by the limited way in which they explore the space of possible solutions. We propose an architecture wh…
Since smaller language models (SLMs) are computationally more efficient but often under-perform compared to larger models, Knowledge Distillation (KD) methods allow for finetuning these smaller models…
We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Althoug…
This position paper argues that large language model (LLM) reasoning should be studied as latent-state trajectory formation rather than as faithful surface chainof- thought (CoT). This matters because…
Recent progress in Large Reasoning Models (LRMs) has significantly enhanced the reasoning abilities of Large Language Models (LLMs), empowering them to tackle increasingly complex tasks through reflec…
Abstract reasoning is a key ability for an intelligent system. Large language models (LMs) achieve above-chance performance on abstract reasoning tasks, but exhibit many imperfections. However, human …
“Fields Medal winner Terence Tao once shared his experiences solving hard math problems1: “When I was a kid, I had a romanticized notion of mathematics, that hard problems were solved in Eureka moment…
 Recent advances in Large Language Models (LLMs) have led to an emergent ability o…
Answering questions that require multi-hop reasoning at web-scale necessitates retrieving multiple evidence documents, one of which often has little lexical or semantic relationship to the question. T…
“However, chain-of-thought prompting has a key limitation—it often performs poorly on tasks that require generalization of solving problems harder than the demonstration examples, such as compositiona…
Inference-time computation has emerged as a promising scaling axis for improving large language model reasoning. However, despite yielding impressive performance, the optimal allocation of inference-t…
To address this issue, some studies employ the approach of propositional logic to further enhance logical reasoning abilities of LLMs. However, the potential omissions in the extraction of logical exp…
Large Language Models (LLMs) have demonstrated significant improvements in reasoning capabilities through supervised fine-tuning and reinforcement learning. However, when training reasoning models, th…
Multi-hop question answering requires models to gather information from different parts of a text to answer a question. Most current approaches learn to address this task in an end-to-end way with neu…
Time series forecasting is not just numerical extrapolation, but often requires reasoning with unstructured contextual data such as news or events. While specialized Time Series Foundation Models (TSF…
Recently, there has been significant progress in teaching language models to perform step-bystep reasoning to solve complex numerical reasoning tasks. Chain-of-thoughts prompting (CoT) is the state-of…
Process Reward Models (PRMs) have recently emerged as a powerful framework for supervising intermediate reasoning steps in large language models (LLMs). Previous PRMs are primarily trained on model fi…
Chain-of-Thought (CoT) prompting has improved the reasoning performance of large language models (LLMs), but it remains unclear why it works and whether it is the unique mechanism for triggering reaso…
We provide evidence of performative chain-ofthought (CoT) in reasoning models, where a model becomes strongly confident in its final answer, but continues generating tokens without revealing its inter…
Human-written text is the culmination of an underlying thought process—when we write, there is often an internal dialogue that clarifies or even determines the written word. However, modern language m…
We introduce S1-Bench, a novel benchmark designed to evaluate Large Reasoning Models’ (LRMs) performance on simple tasks that favor intuitive system 1 thinking rather than deliberative system 2 reason…
“Although language models have demonstrated remarkable success across a range of NLP tasks, their ability to demonstrate reasoning is often seen as a limitation, which cannot be overcome solely by inc…
Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning with…
Large Language Models (LLMs) have achieved impressive success across a wide range of reasoning tasks, particularly when enhanced with Chain-of-Thought (CoT) prompting, where models generate intermedia…
Chain-of-Thought (CoT) reasoning enables Large Language Models (LLMs) to solve complex reasoning tasks by generating intermediate reasoning steps. However, most existing approaches focus on hard token…
Intermediate token generation (ITG), where a model produces output before the solution, has been proposed as a method to improve the performance of language models on reasoning tasks. These intermedia…
Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved …
Large Language Models (LLMs) often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correc…
Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limit…
Large language models (LLMs) have shown strong performance across natural language reasoning tasks, yet their reasoning processes remain brittle and difficult to interpret. Prompting techniques like C…
Self-detection for Large Language Models (LLMs) seeks to evaluate the trustworthiness of the LLM’s output by leveraging its own capabilities, thereby alleviating the issue of output hallucination. How…
Context compression aims to shorten long context inputs with minimal information loss for LLM inference acceleration. While existing methods have shown promise, they typically rely on complex compress…
We argue that analyzing reasoning traces at the sentence level is a promising approach to understanding reasoning processes. We present three complementary attribution methods: (1) a black-box method …
How cost-effectively can strong reasoning abilities be achieved in language models? Driven by this fundamental question, we present Tina, a family of tiny reasoning models achieved with high cost-effi…
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra “thinking” really helpful?…
Chain-of-Thought (CoT) is an efficient prompting method that enables the reasoning ability of large language models by augmenting the query using multiple examples with multiple intermediate steps. De…
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inferenc…
Self-distillation has emerged as an effective post-training paradigm for LLMs, often improving performance while shortening reasoning traces. However, in mathematical reasoning, we find that it can re…
Previous works have demonstrated the effectiveness of Chain-of-Thought (COT) prompts and verifiers in guiding Large Language Models (LLMs) through the space of reasoning. However, most such studies ei…