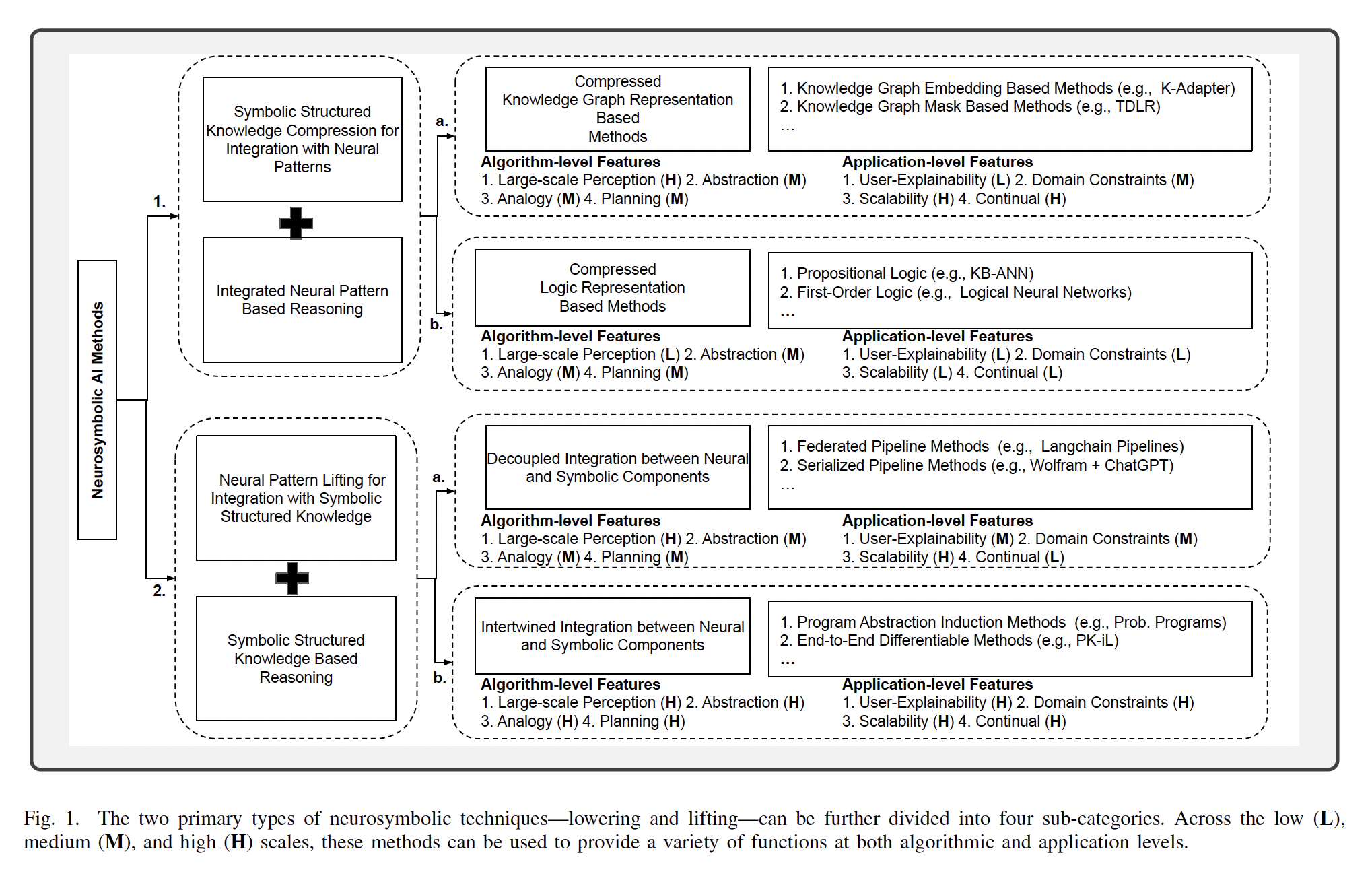
Proactive dialogue systems, related to a wide range of real-world conversational applications, equip the conversational agent with the capability of leading the conversation direction towards achievin…
This survey provides a comprehensive review of research on multi-turn dialogue systems, with a particular focus on multi-turn dialogue systems based on large language models (LLMs). This paper aims to…
Large language models (LLMs) often fail to ask effective questions under uncertainty, making them unreliable in domains where proactive information-gathering is essential for decisionmaking. We presen…
“Aspect-based sentiment classification is a crucial problem in fine-grained sentiment analysis, which aims to predict the sentiment polarity of the given aspect according to its context. Previous work…
[**https://arxiv.org/abs/2404.03820**](https://arxiv.org/abs/2404.03820) Recent advancements in instruction-tuning datasets have predominantly focused on specific tasks like mathematical or logical …
As more social interaction takes place online, researchers have become interested in studying the discourse occurring in online social media. From these studies, researchers can examine how people con…
Several models are proposed in the ConvAI3 challenge (Aliannejadi et al., 2020), aiming to incorporate CQs in the ranking process, mostly proposed based on pre-trained language models. Complementing t…
In the field of natural language processing, open-domain chatbots have emerged as an important research topic. However, a major limitation of existing open-domain chatbot research is its singular focu…
The development of sophisticated artificial intelligence (AI) conversational agents based on large language models raises important questions about the relationship between human norms, values, and pr…
We consider a new perspective on dialog state tracking (DST), the task of estimating a user’s goal through the course of a dialog. By formulating DST as a semantic parsing task over hierarchical repre…
One of the main challenges online social systems face is the prevalence of antisocial behavior, such as harassment and personal attacks. In this work, we introduce the task of predicting from the very…
 To identify effective techniques for answering children’s questions and for presenting explanations in a form t…
 Many important questions (e.g. “How to eat healthier?”) require conversation to establish context and e…
https:// CGMI: Configurable General Multi-Agent Interaction Framework [https://arxiv.org/abs/2308.12503](https://arxiv.org/abs/2308.12503) [[Memory]] [[Role Play]] “With the capabilities of large …
“We introduce a new benchmark, Diplomat, aiming at a unified paradigm for pragmatic reasoning and situated conversational understanding. Compared with previous works that treat different figurative ex…
While large language models have significantly enhanced the effectiveness of discourse relation classifications, it remains unclear whether their comprehension is faithful and reliable. We provide DIS…
Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and generating human-like text, yet they largely operate as reactive agents, responding only when directly promp…
In this paper, we study the task of selecting the optimal response given a user and system utterance history in retrieval-based multi-turn dialog systems. Recently, pre-trained language models (e.g., …
The future of conversational agents will provide users with personalized information responses. However, a significant challenge in developing models is the lack of large-scale dialogue datasets that …
Abstract. This work explores the capability of conversational chatbots powered by large language models (LLMs), to understand and characterize predicate symmetry, a cognitive linguistic function tradi…
Modern GODB have emerged as a solution for highly-connected data, and link oriented queries and algorithms [2]. In fact, they have been a valuable solution in software industry for decades. The implem…
Automatic dialogue summarization is a well-established task that aims to identify the most important content from human conversations to create a short textual summary. Despite recent progress in the …
Decision conferences are structured, collaborative meetings that bring together experts from various fields to address complex issues and reach a consensus on recommendations for future actions or pol…
RAISE, an enhancement of the ReAct framework, incorporates a dual-component memory system, mirroring human short-term and long-term memory, to maintain context and continuity in conversations. It enta…
“Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, …
However, it is unclear whether large language models (LLMs) generate text that reflects human grounding. To this end, we curate a set of grounding acts and propose corresponding metrics that quantify …
The system pipeline consists of the following steps: (1) The IntellAgent system receives a schema of the system database along with either a chatbot system prompt or a document outlining the company p…
Multi-turn conversation has emerged as a predominant interaction paradigm for Large Language Models (LLMs). Users often employ follow-up questions to refine their intent, expecting LLMs to adapt dynam…
we focus on selecting answers, which aims to identify the correct answer from a pool of candidates given a dialogue context. Typically, there are two main branches of approaches to produce answers, i.…
Large Language Models (LLMs) are conversational interfaces. As such, LLMs have the potential to assist their users not only when they can fully specify the task at hand, but also to help them define, …
Personalized dialogue generation, focusing on generating highly tailored responses by leveraging persona profiles and dialogue context, has gained significant attention in conversational AI applicatio…
lexical entrainment (LE), a phenomenon in which speakers in human-human conversations tend to naturally and subconsciously align their lexical choices with those of their interlocutors, leading to mor…
Conversational Artificial Intelligence systems frequently adapt to or mirror the user’s linguistic style, an emergent dynamic that shapes whether the AI is perceived as a tool, a partner, or a hybrid …
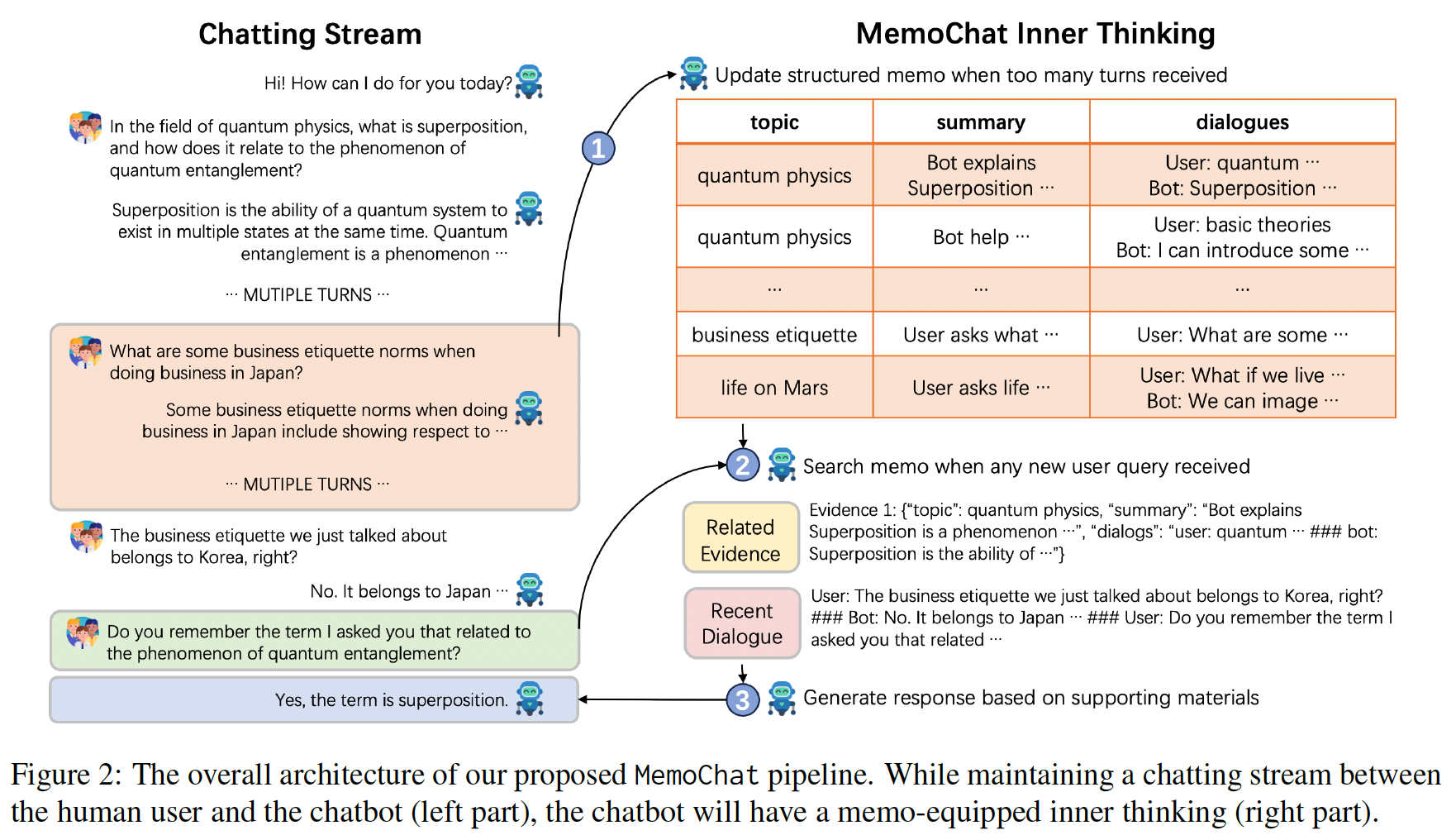 We propose MemoChat, a pipeline for refining instructions that enables large language models (LLMs) to effectively employ self-composed memos…
“Large Language Models (LLMs) are currently capable of generating human-like responses in open-domain tasks [4]. This has led to a new generation of conversational agents, such as chatGPT, which are n…
Abstract Explanations are pervasive in our lives. Mostly, they occur in dialogical form where an explainer discusses a concept or phenomenon of interest with an explainee. Leaving the explainee with a…
When searching for products, the opinions of others play an important role in making informed decisions. Subjective experiences about a product can be a valuable source of information. This is also tr…
Humans communicate with increasing efficiency in multi-turn interactions, by adapting their language and forming ad-hoc conventions. In contrast, prior work shows that LLMs do not naturally show this …
In this paper, we demonstrate the limitations of such methods and rethink what it means for AI to be proactive in multi-party, human-AI conversations. We propose that just like humans, rather than mer…
Multiple studies on content moderation have identified a problem of scale: even if antisocial behavior is a small fraction of all content that gets posted, the sheer size of modern online platforms, t…
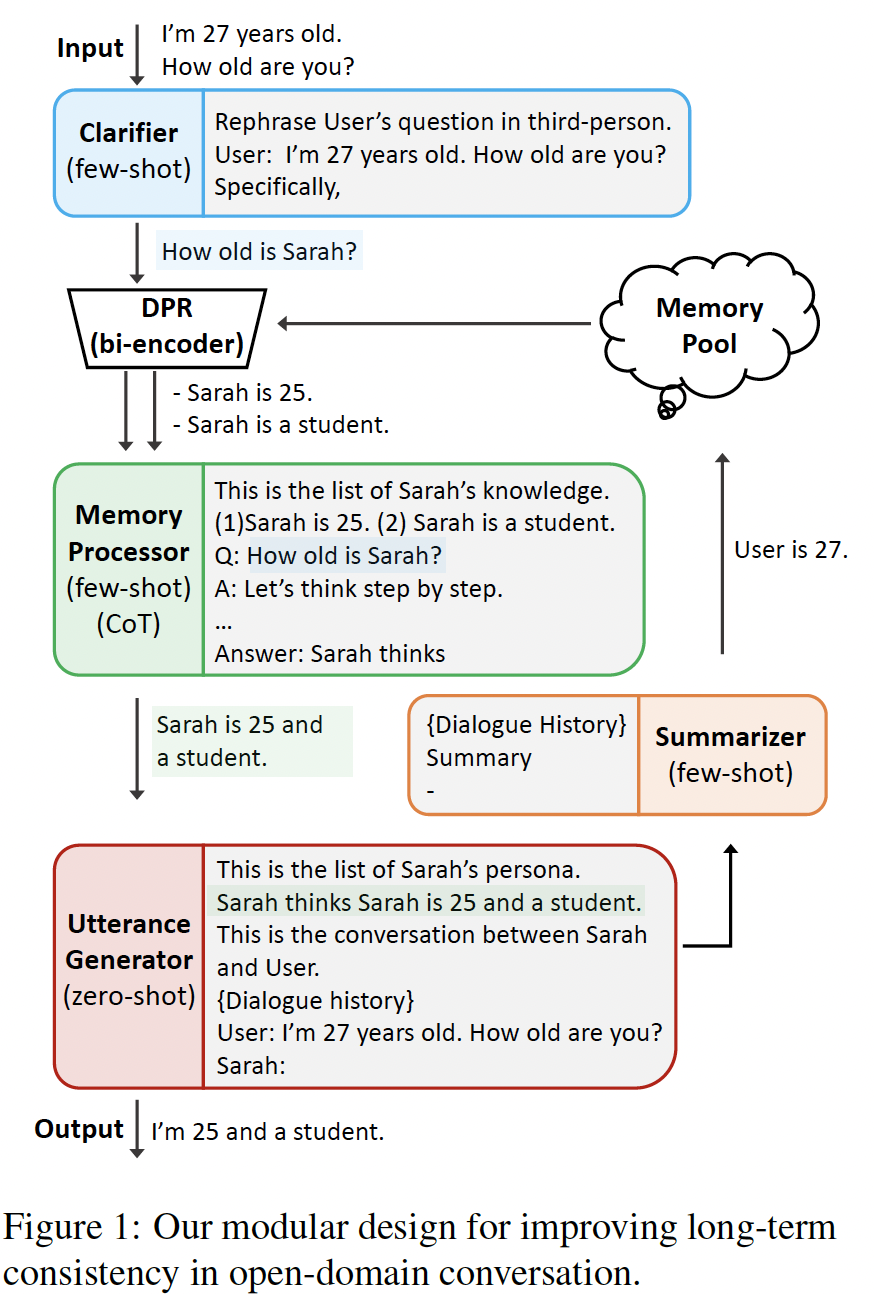 In this paper, we propose MPC (Modular Prompted Chatbot), a new approach for creating…
Social agents powered by large language models (LLMs) can simulate human social behaviors but fall short in handling complex goaloriented social dialogues. Direct Preference Optimization (DPO) has pro…
“Social media (SM) plays an increasingly important role in our lives. As of 2021, seven out of ten US adults use at least one social media platform like Facebook, Twitter, Instagram, or Pinterest [3].…
Large language models (LLMs) have demonstrated strong potential in clinical question answering, with recent multi-agent frameworks further improving diagnostic accuracy via collaborative reasoning. Ho…
Large language models (LLMs) possess strong persuasive capabilities that outperform humans in head-to-head comparisons. Users report consulting LLMs to inform major life decisions in relationships, me…
Humans spontaneously use increasingly efficient language as interactions progress, by adapting and forming ad-hoc conventions. This phenomenon has been studied extensively using reference games, showi…
Many real-world open-domain conversation applications have specific goals to achieve during open-ended chats, such as recommendation, psychotherapy, education, etc. We study the problem of imposing co…
We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs i…
We describe a system for building task oriented dialogue systems combining the in context learning abilities of large language models (LLMs) with the deterministic execution of business logic. LLMs ar…
“Structured Complex Task Decomposition (SCTD) is the problem of breaking down a complex real-world task (such as planning a wedding) into a directed acyclic graph over individual steps that contribute…
There are widespread fears that conversational AI could soon exert unprecedented influence over human beliefs. Here, in three large-scale experiments (N=76,977), we deployed 19 LLMs—including some pos…
it is important to evaluate not only each response but also the user’s overall dialogue impression. For example, improving the dialogue system’s consistency of responses, personality, and empathy will…
we present a first corpus for computational research on how to explain in dialogues (Section 3). Where possible, we followed the literature, but the lack of research on human interaction in explainin…