For instance, the question When did Marie Curie discover Uranium? cannot be answered as a typical when question without addressing the false assumption Marie Curie discovered Uranium. In this work, we…
Large-scale survey tools enable the collection of citizen feedback in opinion corpora. Extracting the key arguments from a large and noisy set of opinions helps in understanding the opinions quickly a…
Standard practice for evaluating the performance of machine learning models for argument mining is to report different metrics such as accuracy or F1. However, little is usually known about the model’…
Abstract—In this technical note we suggest a novel approach to discover temporal (related and unrelated to language dilation) and personality (authorship attribution) aspects in historical datasets. W…
While textual frequency has been validated as relevant to human cognition in reading speed, its relatedness to Large Language Models (LLMs) is seldom studied. We propose a novel research direction in …
Dishonesty is far from a new phenomenon. But as chatbots, online forms, and other digital interfaces grow more and more common across a wide range of customer service applications, bending the truth t…
In this paper we explore a new theory of discourse structure that stresses the role of purpose and processing in discourse. In this theory, discourse structure is composed of three separate but interr…
The remarkable success of pretrained language models has motivated the study of what kinds of knowledge these models learn during pretraining. Reformulating tasks as fillin-the-blanks problems (e.g., …
Extracting metaphors and analogies from free text requires high-level reasoning abilities such as abstraction and language understanding. Our study focuses on the extraction of the concepts that form …
Large Language Models (LLMs) are frequently used for multi-faceted language generation and evaluation tasks that involve satisfying intricate user constraints or taking into account multiple aspects a…
Communication among humans relies on conversational grounding, allowing interlocutors to reach mutual understanding even when they do not have perfect knowledge and must resolve discrepancies in each …
Ambiguous words are often found in modern digital communications. Lexical ambiguity challenges traditional Word Sense Disambiguation (WSD) methods, due to limited data. Consequently, the efficiency of…
Stance detection is an active task in natural language processing (NLP) that aims to identify the author’s stance towards a particular target within a text. Given the remarkable language understanding…
In this paper, we introduce Collaborative Rational Speech Act (CRSA), an information-theoretic (IT) extension of RSA that models multi-turn dialog by optimizing a gain function adapted from rate-disto…
For example, pride may be impacted by depression in a unique way. Gruber et al. (2011) showed that pride, a positive emotion relating to the self, is inversely correlated with depression, which is oft…
Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tas…
The discovery that “next-token predictor” language models can fluently produce text has important but underappreciated theoretical implications. Most notably, their success demonstrates that fully rel…
We consider a new perspective on dialog state tracking (DST), the task of estimating a user’s goal through the course of a dialog. By formulating DST as a semantic parsing task over hierarchical repre…
Those models take a contrastive learning approach, where they build binary classifiers to differentiate positive, or coherent examples from negative, or incoherent dialogues. Those classifiers are usu…
An important part of Cognitive Behavioral Therapy (CBT) is to recognize and restructure certain negative thinking patterns that are also known as cognitive distortions. This project aims to detect the…
Rating scales have shaped psychological research, but are resource-intensive and can burden participants. Large Language Models (LLMs) offer a tool to assess latent constructs in text. This study intr…
The primary clinical manifestation of anxiety is worry associated cognitive distortions, which are likely expressed at the discourse-level of semantics. discourse patterns of causal explanations, amo…
While large language models have significantly enhanced the effectiveness of discourse relation classifications, it remains unclear whether their comprehension is faithful and reliable. We provide DIS…
Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and generating human-like text, yet they largely operate as reactive agents, responding only when directly promp…
Here, we evaluate LLMs using a distinction between formal linguistic competence—knowledge of linguistic rules and patterns—and functional linguistic competence—understanding and using language in the …
Abstract. This work explores the capability of conversational chatbots powered by large language models (LLMs), to understand and characterize predicate symmetry, a cognitive linguistic function tradi…
End-to-end task-oriented dialogue (TOD) systems have achieved promising performance by leveraging sophisticated natural language understanding and natural language generation capabilities of pre-train…
significant emphasis was placed on the development of prompts used to guide the Large LanguageModel (LLM). This process was intricate and involved multiple stages to ensure that the prompts were effec…
In this study, we wish to showcase the unique utility of large language models (LLMs) in financial semantic annotation and alpha signal discovery. Leveraging a corpus of company-related tweets, we use…
Ensuring complex systems meet regulations typically requires checking the validity of assurance cases through a claim-argument-evidence framework. Some challenges in this process include the complicat…
However, recently McKenna et al. (2023a) has pointed out that LLMs are severely affected by an attestation bias when performing inference tasks. Given the question of whether premise P entails hypothe…
The integration of Natural Language Processing (NLP) and AI into legal tasks is a natural progression, given the linguistic nature of law. This combination allows for more efficient and accurate analy…
This paper aims to quantitatively evaluate the performance of ChatGPT, an interactive large language model, on inter-sentential relations such as temporal relations, causal relations, and discourse re…
Natural language explanations play a fundamental role in Natural Language Inference (NLI) by revealing how premises logically entail hypotheses. Recent work has shown that the interaction of large lan…
Projective content is utterance content that a speaker may be taken to be committed to even when the expression associated with the content occurs embedded under an entailment-canceling operator (e.g.…
large language models can generate cognitive tasks, specifically category learning tasks, that match the statistics of real-world tasks, deriving rational agents adapted to these tasks using the frame…
Neural language models (LMs) represent facts about the world described by text. Sometimes these facts derive from training data (in most LMs, a representation of the word banana encodes the fact that …
However, human sarcasm understanding is often considered an intuitive and holistic cognitive process, in which various linguistic, contextual, and emotional cues are integrated to form a comprehensive…
Ensuring that online discussions are civil and productive is a major challenge for social media platforms. Such platforms usually rely both on users and on automated detection tools to flag inappropri…
These implicit assumptions, known as presuppositions, refer to background knowledge or shared beliefs assumed to be part of the common ground between interlocutors (Stalnaker, 1973). Presuppositions a…
While fine-tuning LLMs on NLI corpora improves their inferential performance, the underlying mechanisms driving this improvement remain largely opaque. In this work, we conduct a series of experiments…
Large Language Models (LLMs) demonstrate increasingly human-like abilities across a wide variety of tasks. In this paper, we investigate whether LLMs like ChatGPT can accurately infer the psychologica…
“Large Language Models (LLMs) have demonstrated remarkable capabilities in various NLP tasks. However, previous works have shown these models are sensitive towards prompt wording, and few-shot demonst…
Abstract—The performance of large language models (LLMs) has recently improved to the point where models can perform well on many language tasks. We show here that—for the first time—the models can al…
Humans perceive discrete events such as "restaurant visits" and "train rides" in their continuous experience. One important prerequisite for studying human event perception is the ability of researche…
lexical entrainment (LE), a phenomenon in which speakers in human-human conversations tend to naturally and subconsciously align their lexical choices with those of their interlocutors, leading to mor…
In the recent past, a popular way of evaluating natural language understanding (NLU), was to consider a model’s ability to perform natural language inference (NLI) tasks. In this paper, we investigate…
The basic question-answering format of large language models involves inputting a prompt and receiving a response, and the quality of the prompt directly impacts the effectiveness of the response. Aut…
This study focused on three main research objectives: analyzing the methods used to identify deceptive online consumer reviews, evaluating insights provided by multi-method automated approaches based …
Abstract Metaphorical meaning is not a flat mapping between concepts, but a complex cognitive phenomenon that integrates multiple levels of interpretation. In this paper, we propose a stratified mode…
Abstract: Large language models (LLMs) are often portrayed as merely imitating linguistic patterns without genuine understanding. We argue that recent findings in mechanistic interpretability (MI), th…
Leveraging a comprehensively curated entailment verification benchmark, we evaluate both human and LLM performance across various reasoning categories. Our benchmark includes datasets from three categ…
However, recent works show that LLMs still suffer from hallucinations in NLI due to attestation bias, where LLMs overly rely on propositional memory to build shortcuts. To solve the issue, we design a…
The current literature on presupposition focuses almost exclusively on the projection problem: the question of how and why the presuppositions of atomic clauses are projected to complex sentences whic…
A recurrent claim, coming from different approaches to pragmatics, argumentation theory and related disciplines, is that informative presuppositions have a special persuasive force. My aim in this pap…
Humans communicate with increasing efficiency in multi-turn interactions, by adapting their language and forming ad-hoc conventions. In contrast, prior work shows that LLMs do not naturally show this …
Best practice and descriptive research claim that presuppositions, such as the “too” in “,” increase the persuasiveness of arguments. Surprisingly, there is hardly any causal evidence for this claim. …
Abstract: Discourses can be treated as instances of knowledge. The dynamic space in which the trajectories of these discourses are described can be regarded as a model of knowledge. Such a space is ca…
Investigating the reasoning abilities of transformer models, and discovering new challenging tasks for them, has been a topic of much interest. Recent studies have found these models to be surprisingl…
To improve the reading experience, many news sites organize news into topical collections, called stories. In this work, we present an approach for implementing real-time story identification for a ne…
Recent years, have seen the rise of large language models (LLMs), where practitioners use task-specific prompts; this was shown to be effective for a variety of tasks. However, when applied to semanti…
Though preceding work in computational argument quality (AQ) mostly focuses on assessing overall AQ, researchers agree that writers would benefit from feedback targeting individual dimensions of argum…
Abstract—Topic discovery in scientific literature provides valuable insights for researchers to identify emerging trends and explore new avenues for investigation, facilitating easier scientific infor…
Languages continually evolve in response to societal events, resulting in new terms and shifts in meanings. These changes have significant implications for computer applications, including automatic t…
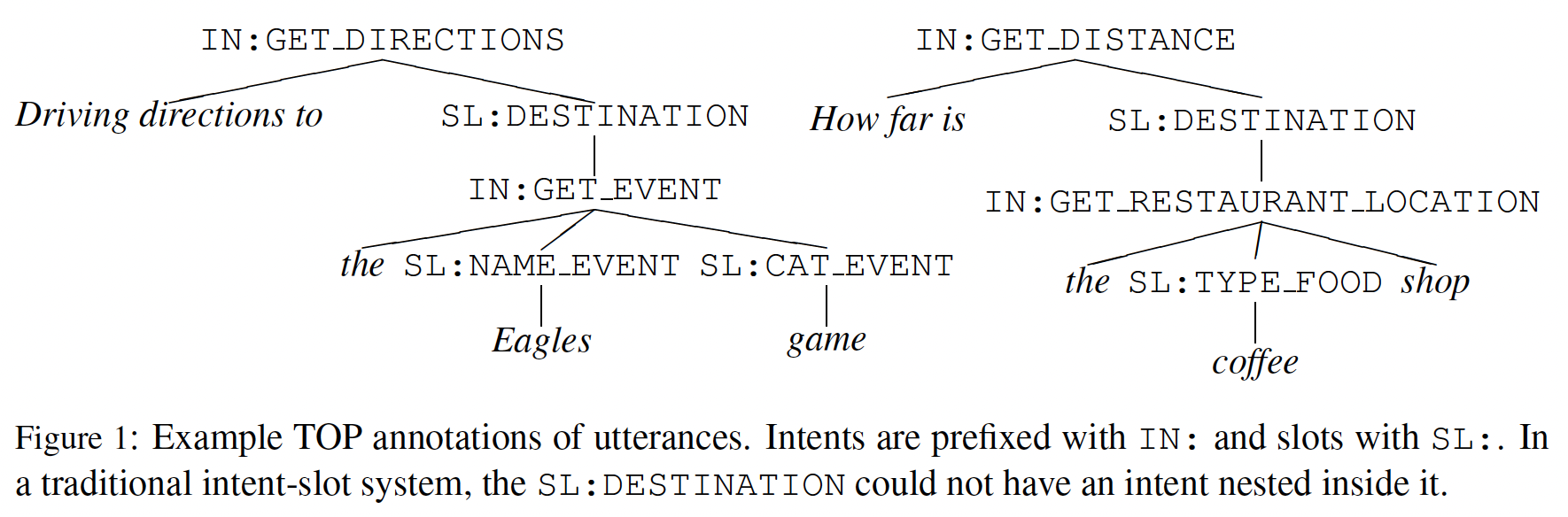 Task oriented dialog systems typically first parse user utterances to semantic frames comprised of intents and s…
Psychological research consistently finds that human ratings of words across diverse semantic scales can be reduced to a low-dimensional form with relatively little information loss. We find that the …
We evaluate LLMs’ language understanding capacities on simple inference tasks that most humans find trivial. Specifically, we target (i) grammatically-specified entailments, (ii) premises with evident…
We establish two biases originating from pretraining which predict much of their behavior, and show that these are major sources of hallucination in generative LLMs. First, memorization at the level o…
The implementation of prompting strategies represents a significant departure from traditional NLP model training methods. By employing these strategies, LLMs can generate predictions without the exte…
We describe a system for building task oriented dialogue systems combining the in context learning abilities of large language models (LLMs) with the deterministic execution of business logic. LLMs ar…
“Structured Complex Task Decomposition (SCTD) is the problem of breaking down a complex real-world task (such as planning a wedding) into a directed acyclic graph over individual steps that contribute…
There are widespread fears that conversational AI could soon exert unprecedented influence over human beliefs. Here, in three large-scale experiments (N=76,977), we deployed 19 LLMs—including some pos…
Abstract. Some accounts of presupposition projection predict that content’s consistency with the Common Ground influences whether it projects (e.g., Heim 1983; Gazdar 1979a,b). I conducted an experime…
Consumers of services and products exhibit a wide range of behaviors on social networks when they are dissatisfied. In this paper, we consider three types of cynical expressions – negative feelings, s…
Representing discourse as argument graphs facilitates robust analysis. Although computational frameworks for constructing graphs from monologues exist, there is a lack of frameworks for parsing dialog…
We study the learnability of English filler—gap dependencies and the “island” con- straints on them by assessing the generalizations made by autoregressive (incremental) language models that use deep …
Using arbitrary natural language statements within reinforcement learning presents several challenges. First, a mapping between language and objects/actions must implicitly or explicitly be learned, a…
When producing deceptive narratives, liars employ verbal strategies to create false beliefs in the interacting partners and are thus involved in a specific and temporary psychological and emotional st…
We explore the task of improving persona consistency of dialogue agents. Recent models tackling consistency often train with additional Natural Language Inference (NLI) labels or attach trained extra …
We investigate how word meanings are represented in the transformer language models. Specifically, we focus on whether transformer models employ something analogous to a lexical store - where each wor…