The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek- R1 has generated widespread social impa…
Reasoning has become a central capability in large language models. Recent research has shown that reasoning performance can be improved by looping an LLM’s layers in the latent dimension, resulting i…
System 1 thinking is fast, automatic, and intuitive, operating effortlessly and often unconsciously. It relies on neural pathways that enable rapid processing, especially in situations needing quick r…
1 Introduction Reinforcement learning (RL) has emerged as a new scaling paradigm for enhancing the capabilities of large language models (LLMs) by enabling thinking abilities [52]. Given a prompt, RL…
Can LLM agents explore codebases and reason about code semantics without executing the code? We study this capability, which we call agentic code reasoning, and introduce semi-formal reasoning: a stru…
Abstract: Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in close…
Why do thinking language models like DeepSeek R1 outperform their base counterparts? Despite consistent performance gains, it remains unclear to what extent thinking models learn entirely new reasonin…
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to human…
Abstract: Large Language Models (LLMs) have demonstrated significant capabilities in understanding and generating human language, contributing to more natural interactions with complex systems. Howeve…
Large Language Models (LLMs) have achieved notable performance across a wide range of natural language understanding and generation tasks, from open-ended dialogue and code synthesis to mathematical r…
Their seeming versatility has however led many researchers to wonder whether they can also do well on planning and reasoning tasks typically associated with System 2 competency. Nothing in the traini…
We investigate the extent to which contemporary Large Language Models (LLMs) can engage in exploration, a core capability in reinforcement learning and decision making. We focus on native performance …
Narrative comprehension on long stories and novels has been a challenging domain attributed to their intricate plotlines and entangled, often evolving relations among characters and entities. Given th…
While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computat…
Despite the recent advancements in language models (LMs), their ability to solve complex problems remains limited. This paper introduces Cumulative Reasoning (CR), a novel approach that utilizes LMs c…
Large language models solve complex tasks by generating long reasoning chains, achieving higher accuracy at the cost of increased computational cost and reduced ability to isolate functionally relevan…
Chain-of-Thought (CoT) reasoning has become a powerful framework for improving complex problem-solving capabilities in Multimodal Large Language Models (MLLMs). However, the verbose nature of textual …
To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools…
The recent advent of reasoning models like OpenAI’s o1 was met with excited speculation by the AI community about the mechanisms underlying these capabilities in closed models, followed by a rush of r…
Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaq…
Recent advances in artificial intelligence (AI) have produced highly capable and controllable systems. This creates unprecedented opportunities for structured reasoning as well as collaboration among …
Many real-world tasks require language models (LMs) to reason over complex contexts that exceed their parametric knowledge. This calls for context learning, where LMs directly learn relevant knowledge…
However, the sequential decision making setting poses additional challenges having a lower tolerance for errors since the environment’s stochasticity or the agent’s actions can lead to unseen, and som…
How should future neural reasoning systems implement extended computation? Recursive Reasoning Models (RRMs) offer a promising alternative to autoregressive sequence extension by performing iterative …
We present Quasar-1, a novel architecture that introduces temperature-guided reasoning to large language models through the Token Temperature Mechanism (TTM) and Guided Sequence of Thought (GSoT). Our…
Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI. Current large language models (LLMs) primarily employ Chain-of-Thought (CoT…
 Large language models (LLMs) have demonstrated remarkable capabilities …
We introduce a new paradigm for building large causal models (LCMs) that exploits the enormous potential latent in today’s large language models (LLMs). We describe our ongoing experiments with an imp…
Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on hard …
Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical diffi…
Large Language Models (LLMs) have shown human-like reasoning abilities but still struggle with complex logical problems. This paper introduces a novel framework, LOGICLM, which integrates LLMs with sy…
With the emergence of advanced reasoning models like OpenAI o3 and DeepSeek-R1, large language models (LLMs) have demonstrated remarkable reasoning capabilities. However, their ability to perform rigo…
Recent language models exhibit strong reasoning capabilities, yet the influence of long-context capacity on reasoning remains underexplored. In this work, we hypothesize that current limitations in re…
Reinforcement Learning with Verifiable Reward (RLVR) is empirically shown to notably enhance the reasoning performance of large language models (LLMs), particularly in mathematics and programming. How…
Neural networks transform high-dimensional data into compact, structured representations, often modeled as elements of a lower dimensional latent space. In this paper, we present an alternative interp…
Reinforcement learning (RL) with outcome-based rewards has achieved significant success in training large language model (LLM) agents for complex reasoning tasks. However, in active reasoning where ag…
Given the rapid advancement of artificial intelligence, understanding the foundations of intelligent behaviour is increasingly important. Active inference, regarded as a general theory of behaviour, o…
it remains contentious whether RL truly expands a model’s reasoning capabilities or merely amplifies high-reward outputs already latent in the base model’s distribution, and whether continually scalin…
We hypothesize that cross-domain generalization arises from shared abstract reasoning prototypes — fundamental reasoning patterns that capture the essence of problems across domains. These prototypes …
Recursion is a prominent feature of human language, and fundamentally challenging for self-attention due to the lack of an explicit recursive-state tracking mechanism. Consequently, Transformer langua…
Abstract: Reasoning requires going beyond pattern matching or memorization of solutions to identify and implement “algorithmic procedures” that can be used to deduce answers to hard problems. Doing so…
“There is a trending paradigm[1; 2; 3; 4; 5; 6; 7; 8] to couple large language models (LLMs) with external plugins or tools, enabling LLMs to interact with environment [9; 10] and retrieve up-to-date …
“While large language models (LLMs) have demonstrated impressive performance across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-though…
such as OpenAI’s o1 and o3, DeepSeek-V3, and Alibaba’s QwQ, have redefined AI’s problem-solving capabilities by extending large language models (LLMs) with advanced reasoning mechanisms. Yet, their hi…
With the growing adoption of large language model agents in persistent real-world roles, they naturally encounter continuous streams of tasks. A key limitation, however, is their failure to learn from…
In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a rea…
we propose Reversal of Thought (RoT), a novel framework aimed at enhancing the logical reasoning abilities of LLMs. RoT utilizes a Preference-Guided Reverse Reasoning warm-up strategy, which integrate…
Reverse thinking plays a crucial role in human reasoning. Humans can reason not only from a problem to a solution but also in reverse, i.e., start from the solution and reason towards the problem. Thi…
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling…
*Table 2. All 39 reasoning modules consisting of high-level cognitive heuristics for problem-solving. We adopt them from Fernando et al.* (_2023_). Reasoning Modules 1 How could I devise an experim…
This paper introduces an approach that uses pretrained LLMs with few-shot chain-of-thought examples to enable strategic reasoning for AI agents. Our approach uses systematically generated demonstratio…
Large language models (LLMs) often fail to learn effective long chain-of-thought (Long CoT) reasoning from human or non-Long-CoT LLMs imitation. To understand this, we propose that effective and learn…
Large language models (LLMs) have exhibited remarkable reasoning and planning capabilities. Most prior work in this area has used LLMs to reason through steps from an initial to a goal state or criter…
Agentic pipelines present novel challenges and opportunities for human-centered explainability. The HCXAI community is still grappling with how best to make the inner workings of LLMs transparent in a…
The core challenge in applying RL to complex reasoning is to identify a sequence of actions that result in positive rewards and provide appropriate supervision for optimization. Outcome supervision pr…
We have witnessed that strong LLMs like Qwen-Math, MiMo, and Phi-4 possess immense reasoning potential inherited from the pre-training stage. With reinforcement learning (RL), these models can improve…
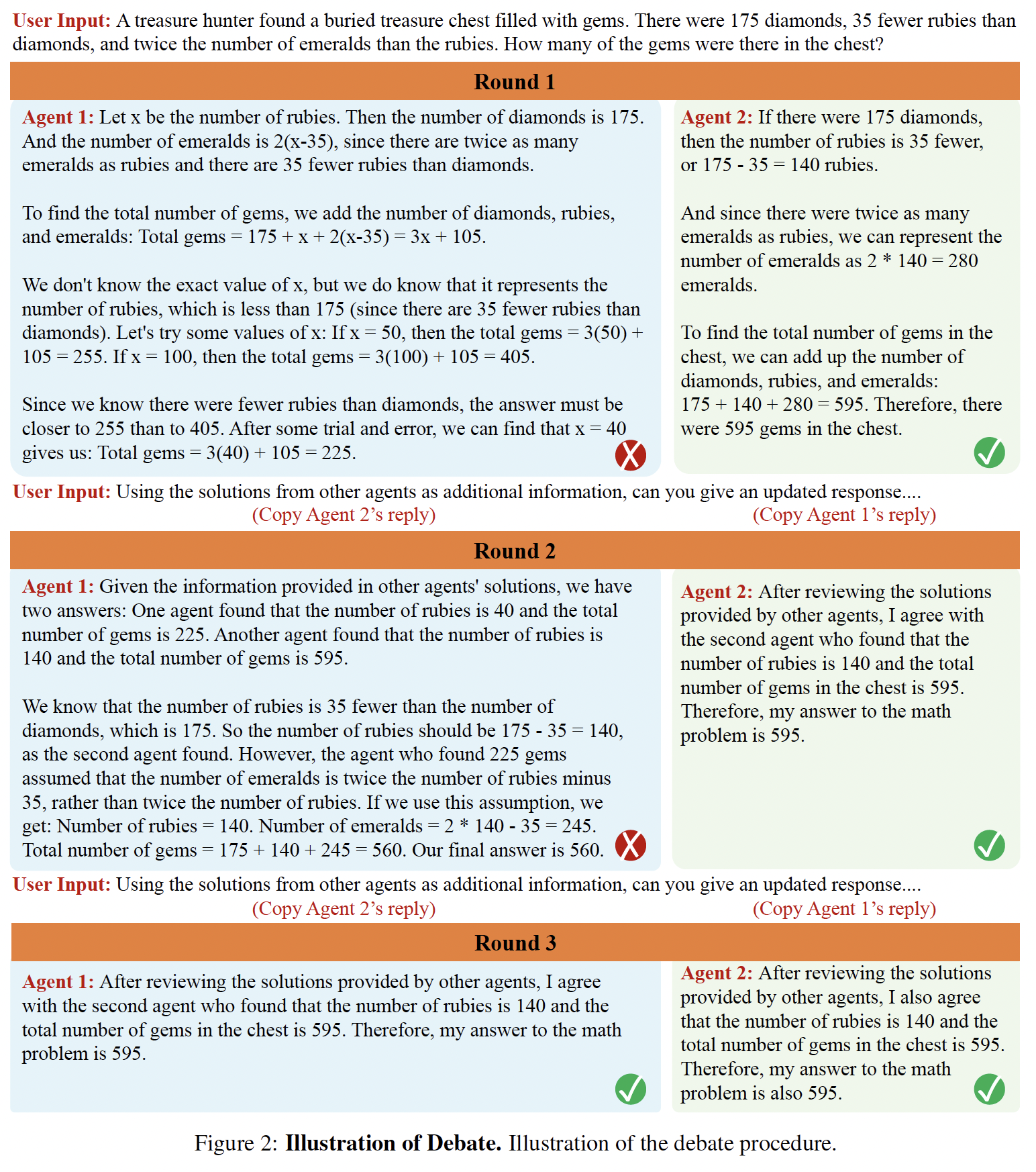
[[Routers]] Despite growing enthusiasm for Multi-Agent LLM Systems (MAS), their performance gains across popular benchmarks often remain minimal compared to single-agent frameworks. This gap highlig…
Despite demonstrating emergent reasoning abilities, Large Language Models (LLMS) often lose track of complex, multi-step reasoning. Existing studies show that providing guidance via decomposing the or…