Evaluating Very Long-Term Conversational Memory of LLM Agents
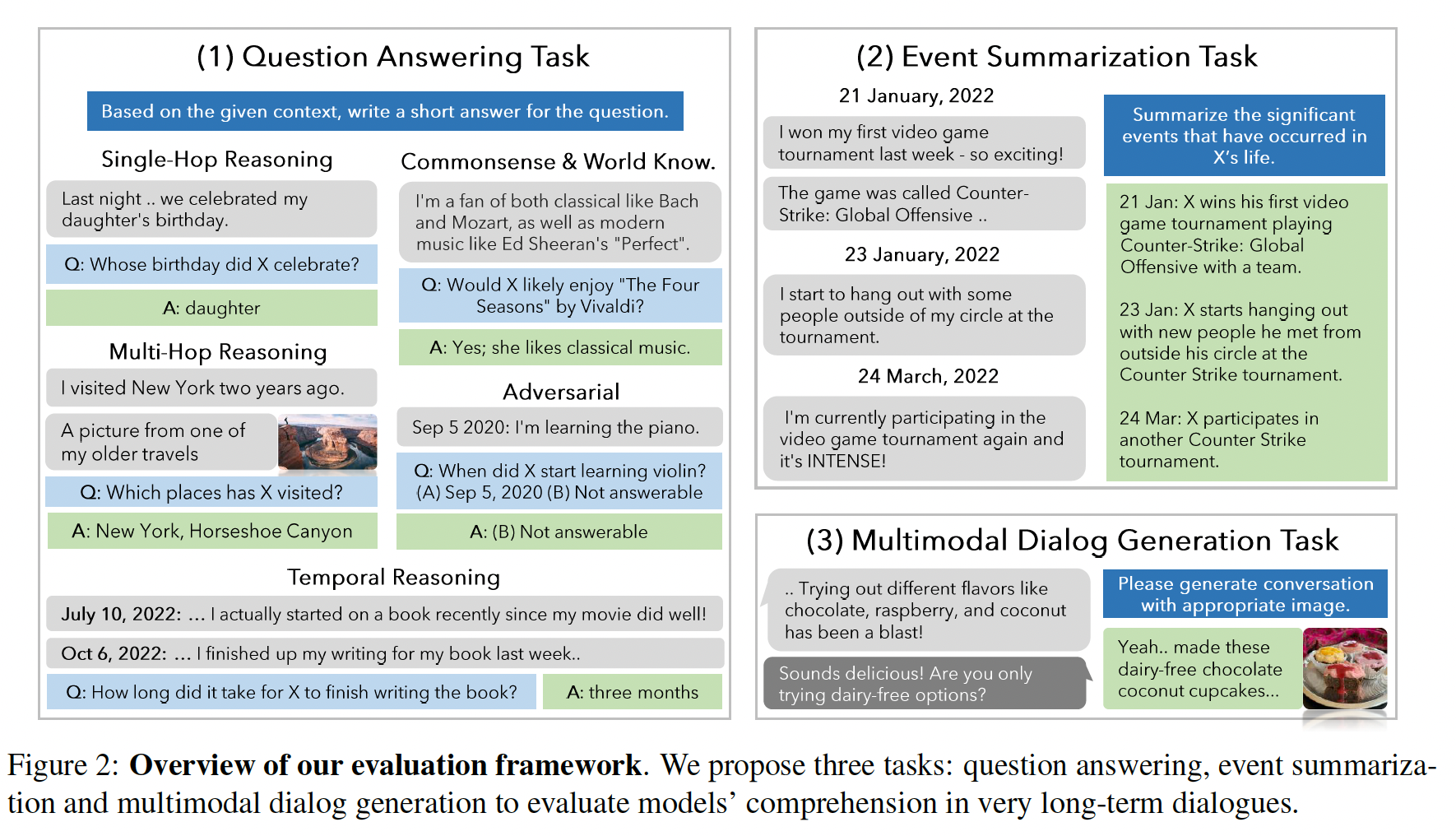
Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning no more than five chat sessions. Despite advancements in longcontext large language models (LLMs) and retrieval augmented generation (RAG) techniques, their efficacy in very long-term dialogues remains unexplored. To address this research gap, we introduce a machine-human pipeline to generate high-quality, very longterm dialogues by leveraging LLM-based agent architectures and grounding their dialogues on personas and temporal event graphs. Moreover, we equip each agent with the capability of sharing and reacting to images. The generated conversations are verified and edited by human annotators for long-range consistency and grounding to the event graphs. Using this pipeline, we collect LOCOMO, a dataset of very longterm conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions. Based on LOCOMO, we present a comprehensive evaluation benchmark to measure long-term memory in models, encompassing question answering, event summarization, and multi-modal dialogue generation tasks.
Introduction. Despite recent advancements in dialogue models based on LLMs for extended contexts (Bertsch et al., 2024; Xiao et al., 2023), as well as the integration of retrieval augmented generation (RAG) techniques (Shuster et al., 2021; Ram et al., 2023; Shi et al., 2023), there is still a need for thorough evaluation of their efficacy in handling very long conversations. Indeed, studies in long-term opendomain dialogues have concentrated on assessing model responses within limited contexts e.g., ∼1K tokens over five chat sessions (Xu et al., 2022; Jang et al., 2023; Zhang et al., 2023). This long term evaluation is crucial for refining engaging chatbots capable of remembering key information from past interactions, to generate empathetic, consistent, and useful responses.
Discussion / Conclusion. We develop a human-machine pipeline to collect LOCOMO, a datset of 50 high-quality very long conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions, and propose an evaluation framework consisting of three tasks that evaluate models’ proficiency in long conversations. Our experiments show that LLMs struggle to comprehend long-term narratives within the dialog and fail to draw temporal and causal connections between events discussed by speakers.