we introduce a hybrid RAG system enhanced through a comprehensive suite of optimizations that significantly improve retrieval quality, augment reasoning capabilities, and refine numerical computation …
“Despite the remarkable ability of large language models (LMs) to comprehend and generate language, they have a tendency to hallucinate and create factually inaccurate output. Augmenting LMs by retrie…
While external information via RAG (Lewis et al., 2020b) can potentially help to fill these gaps, it raises the possibility of irrelevance, thus leading to the error accumulation These methods rely o…
Retrieval-augmented generation (RAG) enhances large language models (LLMs) with external knowledge but still suffers from long contexts and disjoint retrieval–generation optimization. In this work, we…
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs’ ability to…
Retrieval-augmented language model (RALM) represents a significant advancement in mitigating factual hallucination by leveraging external knowledge sources. However, the reliability of the retrieved i…
This paper introduces an approach for training o1-like RAG models that retrieve and reason over relevant information step by step before generating the final answer. Conventional RAG methods usually p…
Retrieval-Augmented Generation (RAG) allows overcoming the limited knowledge of LLMs by extending the input with external information. As a consequence, the contextual inputs to the model become much …
“Large language models (LLMs) have the remarkable ability to solve new tasks with just a few examples, but they need access to the right tools. Retrieval Augmented Generation (RAG) addresses this prob…
Dynamic retrieval augmented generation (RAG) paradigm actively decides when and what to retrieve during the text generation process of Large Language Models (LLMs). There are two key elements of this …
While large language models (LLMs) leverage both knowledge and reasoning during inference, the capacity to distinguish between them plays a pivotal role in model analysis, interpretability, and develo…
Large Language Models (LLMs) have shown remarkable potential in reasoning while they still suffer from severe factual hallucinations due to timeliness, accuracy, and coverage of parametric knowledge. …
Large Language Models (LLMs) equipped with web search capabilities have demonstrated impressive potential for deep research tasks. However, current approaches predominantly rely on either manually eng…
“This paper introduces a new category of domain adaptation in IR that is as-yet unexplored. Here, similar to the zero-shot setting, we assume the retrieval model does not have access to the target doc…
Retrieval-augmented generation (RAG) systems combine large language models (LLMs) with external knowledge retrieval, making them highly effective for knowledge-intensive tasks. A crucial but often und…
Large language models (LLMs) often exhibit limited performance on domain-specific tasks due to the natural disproportionate representation of specialized information in their training data and the sta…
Modern GODB have emerged as a solution for highly-connected data, and link oriented queries and algorithms [2]. In fact, they have been a valuable solution in software industry for decades. The implem…
End-to-end task-oriented dialogue (TOD) systems have achieved promising performance by leveraging sophisticated natural language understanding and natural language generation capabilities of pre-train…
Retrieval-augmented generation has raise extensive attention as it is promising to address the limitations of large language models including outdated knowledge and hallucinations. However, retrievers…
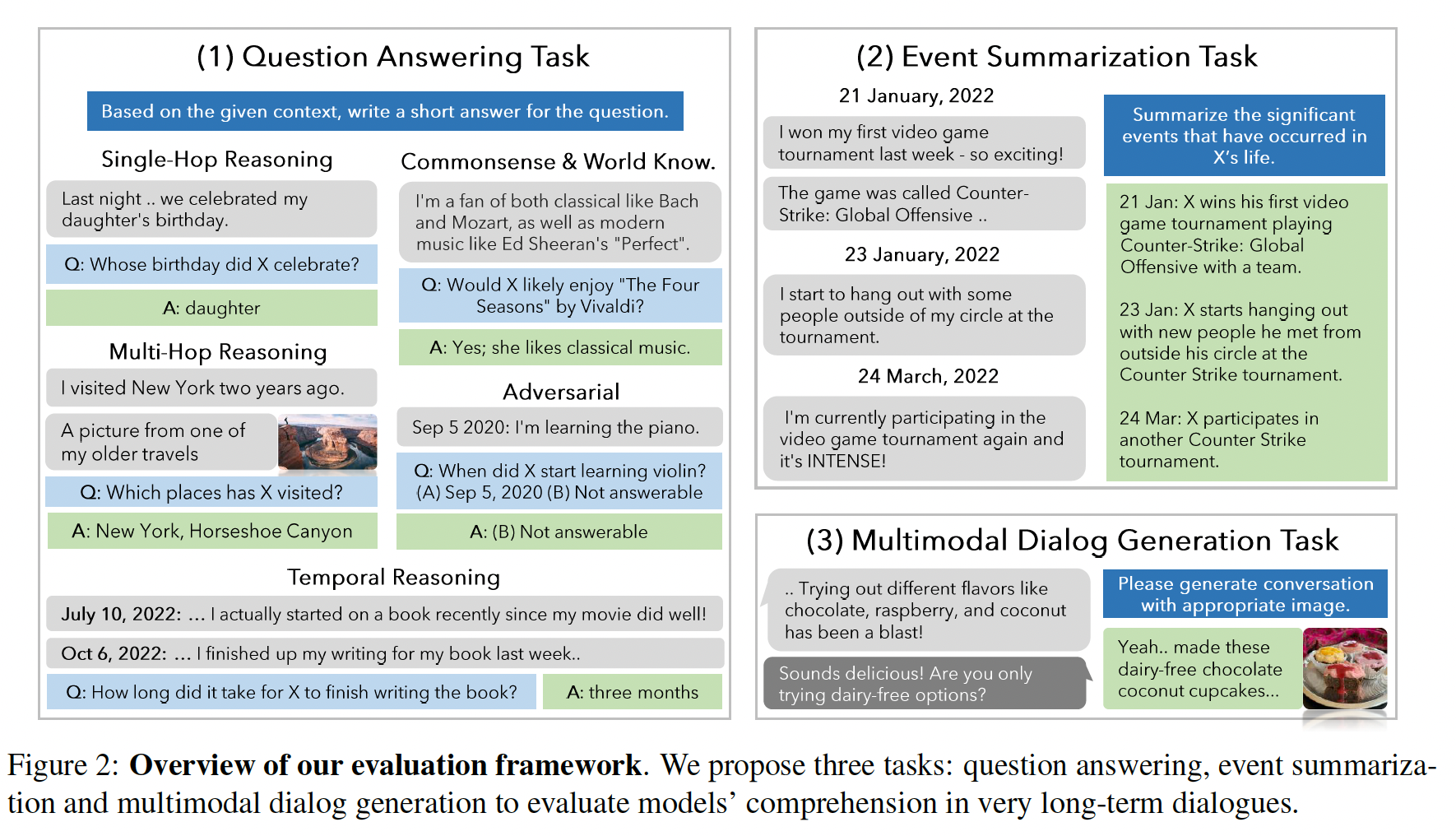 Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning n…
Large Language Models (LLMs) have demonstrated significant performance improvements across various cognitive tasks. An emerging application is using LLMs to enhance retrieval-augmented generation (RAG…
The use of retrieval-augmented generation (RAG) to retrieve relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previous…
In order to thrive in hostile and ever-changing natural environments, mammalian brains evolved to store large amounts of knowledge about the world and continually integrate new information while avoid…
Abstract This paper addresses the challenge of processing long documents using generative transformer models. To evaluate different approaches, we introduce BABILong, a new benchmark designed to asses…
The web serves as a global repository of knowledge, used by billions of people to search for information. Ensuring that users receive the most relevant and up-to-date information, especially in the pr…
Our key contributions are: 1) We conduct the first investigation of the feasibility of using LLMs in intelligence analysis where both evidencebased reasoning and analytical creativity is of utmost …
Large Language Models (LLMs) are prone to hallucinations, and Retrieval-Augmented Generation (RAG) helps mitigate this, but at a high computational cost while risking misinformation. Adaptive retrieva…
However, LLM-based QA struggles with complex QA tasks due to poor reasoning capacity, outdated knowledge, and hallucinations. Several recent works synthesize LLMs and knowledge graphs (KGs) for QA to …
Autonomous agents powered by large language models (LLMs) have the potential to enhance human capabilities, assisting with digital tasks from sending emails to performing data analysis. The abilities …
Personalized dialogue generation, focusing on generating highly tailored responses by leveraging persona profiles and dialogue context, has gained significant attention in conversational AI applicatio…
Large Language Models (LLMs) demonstrate exceptional performance in textual understanding and tabular reasoning tasks. However, their ability to comprehend and analyze hybrid text, containing textual …
Longcontext question answering (LCQA) (Caciularu et al., 2022), which has been recently advanced significantly by LLMs, is a complex task that requires reasoning over a long document or multiple docum…
In traditional RAG framework, the basic retrieval units are normally short. The common retrievers like DPR normally work with 100-word Wikipedia paragraphs. Such a design forces the retriever to searc…
Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. It underpins long-horizon reasoning, continual adaptation, and effective interaction with complex e…
Retrieval-augmented generation have become central in natural language processing due to their efficacy in generating factual content. While traditional methods employ single-time retrieval, more rece…
Retrieval-augmented generation (RAG) augments large language models (LLM) by retrieving relevant knowledge, showing promising potential in mitigating LLM hallucinations and enhancing response quality,…
Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, andmore. These new ben…
Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) are two prominent post-training paradigms for refining the capabilities and aligning the behavior of Large Language Models (LLMs). Existing…
Given a query, HyDE first zero-shot instructs an instruction-following language model (e.g. InstructGPT) to generate a hypothetical document. The document captures relevance patterns but is unreal and…
Large Language Models (LLMs) play powerful, black-box readers in the retrieve-thenread pipeline, making remarkable progress in knowledge-intensive tasks. This work introduces a new framework, Rewrite-…
Retrieval-Augmented Generation (RAG) improves the accuracy and relevance of large language model outputs by incorporating knowledge retrieval. However, implementing RAG in enterprises poses challenges…
Retrieval-augmented generation (RAG) has shown great promise for knowledge-intensive tasks and recently advanced with agentic RAG, where language agents engage in multi-round interactions with externa…
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, while LLMs remain prone to generating hallucinated or outdated responses due to their static internal knowl…
Traditional Retrieval-Augmented Generation (RAG) pipelines rely on similarity-based retrieval and re-ranking, which depend on heuristics such as top-k, and lack explainability, interpretability, and r…
Large Language Models (LLM), conversational assistants have become prevalent for domain use cases. LLMs acquire the ability to contextual question answering through extensive training, and Retrieval A…
Generating unbiased summaries in real-world settings such as political perspective summarization remains a crucial application of Large Language Models (LLMs). Yet, existing evaluation frameworks rely…
This technical report details a novel approach to combining reasoning and retrieval augmented generation (RAG) within a single, lean language model architecture. While existing RAG systems typically r…
theoretical analysis, we provide the first explanation of the RAG ensemble framework from the perspective of information entropy. In terms of mechanism analysis, we have explored the RAG ensemble fram…
Existing studies mostly focus on question scenarios with clear user intents and concise answers. However, it is prevalent that users issue broad, open-ended queries with diverse sub-intents, for which…
A typical RAG workflow usually contains multiple intervening processing steps: query classification (determining whether retrieval is necessary for a given input query), retrieval (efficiently obtaini…
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Ret…
We study the limitations of Large Language Models (LLMs) for the task of response generation in human-machine dialogue. Several techniques have been proposed in the literature for different dialogue t…
Retrieval-augmented generation (RAG) is a key means to effectively enhance large language models (LLMs) in many knowledge-based tasks. However, existing RAG methods struggle with knowledge-intensive r…
Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models (LLMs) and Multi-Modal LLMs (MLLMs). As these models transition from…
Wrong Tool for the Job RAG fails in production because vector embeddings are the wrong choice for determining percentage of sameness. This is easily demonstrated. Consider the following three words: …
Context compression aims to shorten long context inputs with minimal information loss for LLM inference acceleration. While existing methods have shown promise, they typically rely on complex compress…
Retrieval-Augmented Generation (RAG) lifts the factuality of Large Language Models (LLMs) by injecting external knowledge, yet it falls short on problems that demand multistep inference; conversely, p…
Dense retrieval compresses texts into single embeddings ranked by cosine similarity. While efficient for recall, this interface is brittle for identity-level matching: minimal compositional edits (neg…
Non-factoid question-answering (NFQA) poses a significant challenge due to its open-ended nature, diverse intents, and the need for multi-aspect reasoning, which renders conventional factoid QA approa…
Large Language Models (LLMs) have shown remarkable capabilities through two complementary paradigms: Retrieval-Augmented Generation (RAG), which enhances knowledge grounding, and Reinforcement Learnin…
Graph-based retrieval-augmented generation (RAG) enables large language models (LLMs) to ground responses with structured external knowledge from up-to-date knowledge graphs (KGs) and reduce hallucina…
Large language models (LLMs) often suffer from hallucination, generating factually incorrect statements when handling questions beyond their knowledge and perception. Retrieval-augmented generation (R…